
1. Kafka 직렬화/역직렬화 탐구
1.1. 기존 Producer, Consumer의 직렬화/역직렬화 처리 방식
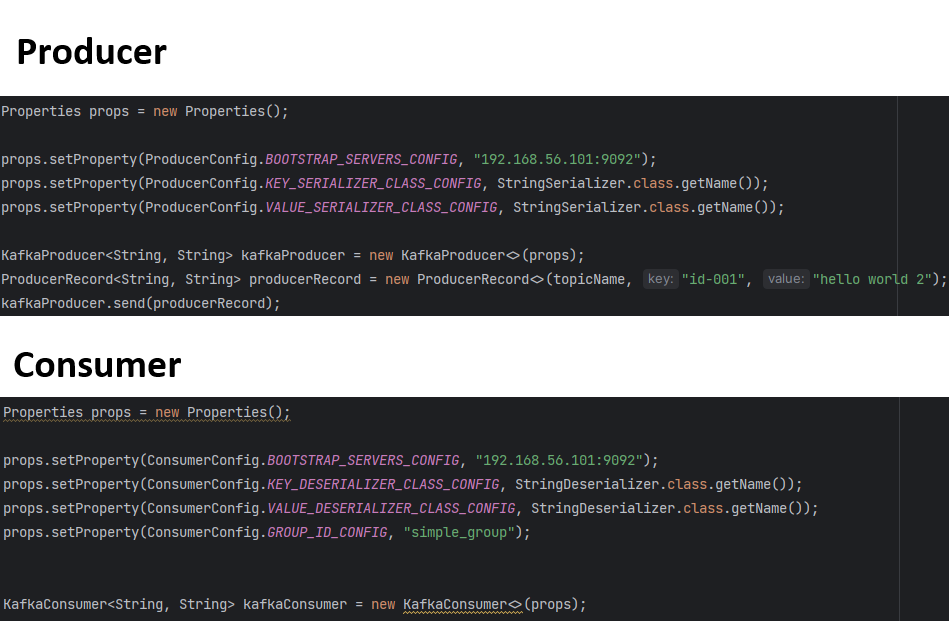
Kafka에서는 데이터를 전송할 때 객체를 그대로 보내지 않고 Byte Array 형태로 변환한다. 이는 네트워크 대역폭, 데이터 압축 효율, 노드 간 통신 포맷 등을 고려한 설계인 것이다. 따라서 Producer와 Consumer를 구현할 때는 기본적으로 StringSerializer와 StringDeserializer 같은 클래스를 사용하여 직렬화/역직렬화를 설정하면 된다.
1.2. Kafka 기본 제공 Serializer/Deserializer

Kafka가 기본적으로 제공하는 직렬화/역직렬화 대상은 String, Integer, Long과 같은 기본 타입 기반 객체에 국한된다. 그러나 실제 업무 환경에서는 단순 문자열이 아닌 다양한 도메인 객체를 주고받는 경우가 많다. 예를 들어 Order라는 객체를 메시지로 교환해야 한다면, 단순히 문자열 직렬화만으로는 한계가 발생하는 것이다.
1.3. 문자열 기반 처리의 한계
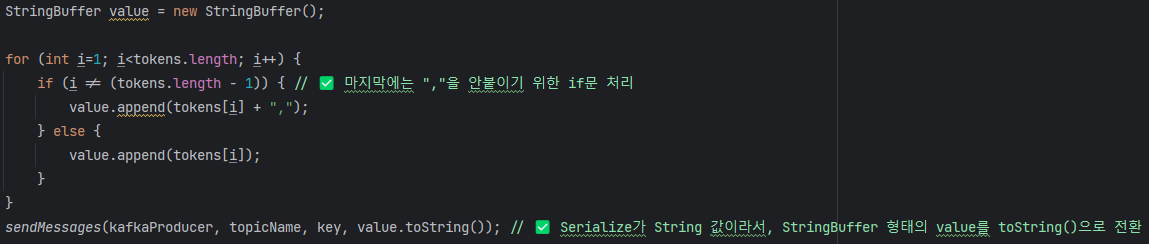
만약 Order라는 커스텀 객체를 단순히 문자열로 처리하려 한다면, 각 필드를 개별적으로 파싱한 뒤 StringBuffer에 append하고, 다시 문자열로 변환하는 번거로운 과정을 거쳐야 한다. 이렇게 하면 코드가 불필요하게 복잡해지고 유지보수도 어려워진다.
1.4. 커스텀 직렬화/역직렬화 필요성

모든 객체에 대해서 이런 부수적인 로직을 구현하는것은 쉬운일이 아니다. 따라서 업무적으로 사용되는 Order등의 데이터를 객체 형태로 전달하기 위해서는 직접 커스텀 객체의 Serializer/Deserializer를 구현함으로써 이 문제를 해결할 수 있다.
2. Kafka Client에서 Custom 객체의 직렬화/역직렬화 구현
2.1. Custom Serializer 구현 방식

Kafka의 Serializer 인터페이스를 구현하면 serialize() 메서드를 오버라이드하여 객체를 Byte Array로 변환할 수 있다. 이후 Kafka Producer 설정 시 props에 해당 커스텀 Serializer 클래스를 등록하면 된다. 여기서 한 가지 의문이 생긴다. 직렬화 로직을 직접 작성해야 할까? 예를 들어 아래와 같이 ByteBuffer를 이용하여 각 필드를 직접 바이트 배열로 변환하는 방식이다.
public byte[] serialize(String topic, Order data) {
int sizeOfName;
int sizeOfDate;
byte[] serializedName;
byte[] serializedDate;
try {
if (data == null)
return null;
serializedName = data.getName().getBytes(encoding);
sizeOfName = serializedName.length;
serializedDate = data.getStartDate().toString().getBytes(encoding);
sizeOfDate = serializedDate.length;
ByteBuffer buf = ByteBuffer.allocate(4 + 4 + sizeOfName + 4 + sizeOfDate);
buf.putInt(data.getID());
buf.putInt(sizeOfName);
buf.put(serializedName);
buf.putInt(sizeOfDate);
buf.put(serializedDate);
return buf.array();
} catch (Exception e) { }
}이 방식은 가능하지만, 필드가 많아질수록 코드가 복잡해지고 에러 발생 가능성도 커진다.
2.2. Jackson Databind 활용
결론부터 말하자면, 직접 바이트 배열 변환 로직을 작성할 필요는 없다. 대신 Jackson Databind 라이브러리를 이용하면 된다. Jackson은 Java 객체를 JSON으로 직렬화하거나 JSON을 Java 객체로 역직렬화할 수 있는 라이브러리이다. 이를 Kafka의 직렬화/역직렬화 과정에 적용하면 매우 간단하게 커스텀 객체를 처리할 수 있다. 예시 코드는 다음과 같다.
ObjectMapper objectMapper = new ObjectMapper();
public byte[] serialize(String topic, OrderModel order) {
byte[] serializedOrder = null;
try {
serializedOrder = objectMapper.writeValueAsBytes(order);
} catch (JsonProcessingException e) {
logger.error("Json processing exception:" + e.getMessage());
}
return serializedOrder;
}
이처럼 Jackson을 활용하면 객체를 JSON 기반의 바이트 배열로 직렬화할 수 있으며, 역직렬화 시에도 동일한 방법을 적용하면 된다. 결과적으로 Kafka 환경에서 커스텀 객체를 효율적으로 주고받을 수 있게 되는 것이다.
implementation 'com.fasterxml.jackson.core:jackson-databind:2.13.3'
implementation 'com.fasterxml.jackson.datatype:jackson-datatype-jsr310:2.13.3'📌 정리하자면, Kafka는 기본적으로 단순 타입만 지원하지만, 실제 서비스에서는 다양한 객체를 주고받아야 한다. 이때 직접 바이트 변환 로직을 작성할 수도 있지만, Jackson과 같은 라이브러리를 이용하면 훨씬 간단하고 안정적인 직렬화/역직렬화 구현이 가능하다는 점이 핵심인 것이다.
3. Producer의 커스텀 객체 직렬화 구현
practice/src/main/java/com/practice/kafka/model/OrderModel.java
public class OrderModel implements Serializable {
public String orderId;
public String shopId;
public String menuName;
public String userName;
public String phoneNumber;
public String address;
public LocalDateTime orderTime;
public OrderModel(String orderId, String shopId, String menuName, String userName,
String phoneNumber, String address, LocalDateTime orderTime) {
this.orderId = orderId;
this.shopId = shopId;
this.menuName = menuName;
this.userName = userName;
this.phoneNumber = phoneNumber;
this.address = address;
this.orderTime = orderTime;
}
// 기본 생성자 및 전체 필드 생성자
// Getter
// Setter
// toString
}practice/src/main/java/com/practice/kafka/producer/OrderSerializer.java
public class OrderSerializer implements Serializer<OrderModel> {
ObjectMapper objectMapper = new ObjectMapper().registerModule(new JavaTimeModule());
public static final Logger logger = LoggerFactory.getLogger(FileProducer.class.getName());
@Override
public byte[] serialize(String topic, OrderModel order) {
byte[] serializedOrder = null;
try {
serializedOrder = objectMapper.writeValueAsBytes(order);
} catch (JsonProcessingException e) {
logger.error("Json 직렬화 오류: " + e.getMessage());
}
return serializedOrder;
}
}practice/src/main/java/com/practice/kafka/producer/OrderSerdeProducer.java
public class OrderSerdeProducer {
public static final Logger logger = LoggerFactory.getLogger(OrderSerdeProducer.class.getName());
public static void main(String[] args) {
String topicName = "order-serde-topic"; // ✅ 토픽 이름
String filePath = "C:\\0. inflearn\\kafka-proj1\\practice\\src\\main\\resources\\pizza_sample.txt"; // ✅ 파일 경로
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.101:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, OrderSerializer.class.getName());
// ✅ kafkaProducer 객체 생성 -> ProducerRecord 생성 -> kafkaProducer.send() 비동기 방식 전송 -> kafkaProducer.close();
KafkaProducer<String, OrderModel> kafkaProducer = new KafkaProducer<>(props);
sendFileMessages(kafkaProducer, topicName, filePath);
kafkaProducer.close();
}
private static void sendFileMessages(KafkaProducer<String, OrderModel> kafkaProducer, String topicName, String filePath) {
String line = ""; // ✅ 라인 변수 선언
final String delimiter = ",";
try {
FileReader fileReader = new FileReader(filePath); // ✅ 파일 리더 객체 생성
BufferedReader bufferedReader = new BufferedReader(fileReader); // ✅ 버퍼 리더 객체 생성
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// ✅ 1000번 반복
while ( (line = bufferedReader.readLine()) != null ) {
String[] tokens = line.split(delimiter); // ✅ ","을 기준으로 split
String key = tokens[0]; // ✅ 키 추출 (P001)
StringBuffer value = new StringBuffer();
OrderModel orderModel = new OrderModel(tokens[1], tokens[2], tokens[3], tokens[4],
tokens[5], tokens[6], LocalDateTime.parse(tokens[7].trim(), formatter));
sendMessages(kafkaProducer, topicName, key, orderModel); // ✅ Serialize가 String 값이라서, StringBuffer 형태의 value를 toString()으로 전환
}
} catch (IOException e) {
logger.info(e.getMessage());
}
}
private static void sendMessages(KafkaProducer<String, OrderModel> kafkaProducer, String topicName, String key, OrderModel orderModel) {
// ✅ key, value 기반으로 ProducerRecord 객체 생성
ProducerRecord<String, OrderModel> producerRecord = new ProducerRecord<>(topicName, key, orderModel);
logger.info("key={}, value={}", key, orderModel);
// ✅ 비동기(콜백) 전송
kafkaProducer.send(producerRecord, (metadata, exception) -> {
if (exception == null) {
logger.info("\n ###### record metadata received ##### \n" +
"partition: " + metadata.partition() + "\n" +
"offset: " + metadata.offset() + "\n" +
"timestamp: " + metadata.timestamp());
} else {
logger.error("exception error from broker" + exception.getMessage());
}
});
}
}
4. Consumer의 커스텀 객체 역직렬화 구현
practice/src/main/java/com/practice/kafka/consumer/OrderDeserializer.java
public class OrderDeserializer implements Deserializer<OrderModel> {
ObjectMapper objectMapper = new ObjectMapper().registerModule(new JavaTimeModule());
public static final Logger logger = LoggerFactory.getLogger(OrderDeserializer.class.getName());
@Override
public OrderModel deserialize(String topic, byte[] data) {
OrderModel orderModel = new OrderModel();
// 역직렬화
try {
orderModel = objectMapper.readValue(data, OrderModel.class);
} catch (IOException e) {
logger.error("역직렬화 실패: " + e.getMessage());
}
return orderModel;
}
}practice/src/main/java/com/practice/kafka/consumer/OrderSerdeConsumer.java
public class OrderSerdeConsumer<K extends Serializable, V extends Serializable> {
public static final Logger logger = LoggerFactory.getLogger(OrderSerdeConsumer.class.getName());
private KafkaConsumer<K, V> kafkaConsumer;
private List<String> topics;
...
public static void main(String[] args) {
String topicName = "order-serde-topic";
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.101:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "file-group");
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// ✅ 반환받는 제네릭 타입에 String -> OrderModel로 변경
OrderSerdeConsumer<String, OrderModel> baseConsumer = new OrderSerdeConsumer<>(props, List.of(topicName));
baseConsumer.initConsumer();
String commitMode = "async";
baseConsumer.pollConsumes(100, commitMode);
baseConsumer.closeConsumer();
}
}
'Kafka > Core' 카테고리의 다른 글
| [ADVANCED #10] Spring 기반의 Kafka 사용 및 운용 (0) | 2026.02.27 |
|---|---|
| [ADVANCED #9] 카프카의 데이터 저장 메커니즘: 파티션, 세그먼트, 인덱스 그리고 로그 정리 정책 (0) | 2025.09.13 |
| [ADVANCED #7][실습] 멀티 브로커 클러스터 구축: 직접 띄우고 확인하는 리플리케이션과 장애 복구 (0) | 2025.09.12 |
| [ADVANCED #6] 클러스터 운영의 핵심: 리플리케이션, ISR, 그리고 리더 선출의 모든 것 (0) | 2025.09.11 |
| [ADVANCED #5][실습] Producer & Consumer 연동 프로젝트: 파일 기반 주문 데이터를 DB로 저장하기 (0) | 2025.09.11 |