
0. 들어가며
마이크로서비스 아키텍처(MSA)에서는 수많은 서비스가 독립적으로 동작하며 서로 통신한다. 이때 "서비스 A가 서비스 B를 어떻게 찾아서 호출할 수 있는가?"라는 근본적인 문제가 발생한다. 서비스 디스커버리(Service Discovery)는 바로 이 문제를 해결하기 위한 핵심 패턴이다.
전통적인 모놀리식 환경에서는 애플리케이션의 위치가 고정되어 있었다. 로드 밸런서의 IP 주소나 고정된 서버 주소를 설정 파일에 하드코딩해도 큰 문제가 없었다. 하지만 클라우드 네이티브 환경에서는 서비스 인스턴스의 IP 주소가 고정적이지 않다. 이때 등장하는 개념이 바로 서비스 디스커버리다.
이번 글에서는 Spring Cloud Netflix Eureka를 중심으로 서비스 디스커버리의 개념과 구현 방법, 그리고 현업에서의 활용 방안까지 상세히 살펴보겠다.
1. MSA의 필수 요소: 서비스 디스커버리 (Service Discovery)

1.1. 문제의 발단: 동적인 서비스 위치
클라우드 환경에서 서비스 인스턴스는 가상 머신(VM)이나 컨테이너 위에서 실행된다. 이들의 네트워크 주소(IP, Port)는 고정되어 있지 않고, 오토 스케일링이나 장애 복구 등의 이유로 동적으로 변하는 것이 일반적이다.
- 동일 머신, 다른 포트: 하나의 머신에서 여러 서비스를 실행할 경우, IP 주소는 동일하지만 각 서비스를 구분하기 위해 포트 번호를 다르게 할당해야 한다. (예: localhost:8080, localhost:8081)
- 다른 머신, 동일 포트: 각 서비스가 개별적인 머신에서 실행될 경우, IP 주소는 다르지만 포트 번호는 동일하게 사용할 수 있다. (예: 192.168.1.10:8080, 192.168.1.11:8080)
이처럼 서비스의 주소는 언제든지 변경될 수 있다. 만약 서비스 A가 서비스 B의 주소를 코드나 설정 파일에 직접 기록(Hard-coding)해 둔다면, 서비스 B의 주소가 바뀔 때마다 서비스 A의 코드를 수정하고 재배포해야 하는 문제가 생긴다. 서비스가 수십, 수백 개로 늘어난다면 이는 사실상 관리가 불가능한 재앙이 된다.
1.2. 해결책: 서비스 디스커버리의 등장
서비스 디스커버리는 이러한 문제를 해결하기 위해 중앙에서 모든 서비스의 위치 정보를 관리하는 '서비스 레지스트리(Service Registry)'를 도입한다. 이는 마치 서비스들의 실시간 '주소록' 또는 '전화번호부'와 같은 역할을 한다. 이 매커니즘은 두 가지 핵심 동작으로 이루어진다.
- 서비스 등록 (Service Registration): 각각의 마이크로서비스는 시작될 때 자신의 서비스 이름과 현재 네트워크 주소(IP, Port)를 서비스 레지스트리에 등록한다. (예: "나는 '주문 서비스'이고, 내 주소는 192.168.1.10:8080이야.")
- 서비스 탐색 (Service Discovery): 다른 서비스를 호출하려는 클라이언트(예: 서비스 A)는 더 이상 특정 IP 주소를 기억할 필요가 없다. 대신, 서비스 레지스트리에 서비스의 논리적인 이름(Service ID)을 질의한다. (예: "'주문 서비스'의 주소가 뭐야?") 그러면 레지스트리는 현재 실행 중인 '주문 서비스' 인스턴스의 실제 주소 목록을 반환해준다.
1.3. 서비스 디스커버리 패턴
서비스 디스커버리에는 두 가지 주요 패턴이 존재한다.
1.3.1. 클라이언트 사이드 디스커버리(Client-Side Discovery)
클라이언트가 직접 서비스 레지스트리에서 서비스 인스턴스 목록을 조회하고, 로드 밸런싱 알고리즘(라운드 로빈, 랜덤, 최소 연결 등)을 사용하여 하나의 인스턴스를 선택한 후 요청을 보내는 방식이다.
- 장점: 비교적 단순한 구조이며, 클라이언트가 로드 밸런싱을 직접 제어할 수 있다. Netflix Eureka와 Spring Cloud LoadBalancer의 조합이 이 패턴의 대표적인 예시다.
- 단점: 서비스 디스커버리 로직이 각 클라이언트에 내장되어야 하므로, 다양한 프로그래밍 언어로 작성된 클라이언트를 지원하려면 각 언어별로 라이브러리를 개발해야 한다.
1.3.2. 서버 사이드 디스커버리(Server-Side Discovery)
클라이언트는 중간에 위치한 로드 밸런서(또는 API 게이트웨이)를 통해 서비스에 접근한다. 로드 밸런서가 서비스 레지스트리에서 인스턴스 목록을 조회하고, 적절한 인스턴스로 요청을 라우팅한다.
- 장점: 디스커버리 로직이 클라이언트로부터 분리되어 있어, 클라이언트는 단순히 로드 밸런서의 주소만 알면 된다. 따라서 다양한 언어와 플랫폼을 지원하기 쉽다.
- 단점: 로드 밸런서가 인프라의 중요한 구성 요소가 되므로, 고가용성 구성이 필수적이다. AWS의 ELB(Elastic Load Balancer)와 Kubernetes의 Kube-proxy가 이 패턴을 구현한다.
2. Spring Cloud Netflix Eureka 개요
Spring Cloud 진영에서는 Netflix에서 개발한 Eureka를 통해 서비스 디스커버리 패턴을 쉽게 구현할 수 있도록 지원한다.
2.1. Eureka란?
Eureka는 Netflix에서 개발한 REST(Representational State Transfer) 기반의 서비스 디스커버리 도구다. Spring Cloud Netflix 프로젝트를 통해 Spring 생태계에 통합되어, Spring Boot 애플리케이션에서 손쉽게 사용할 수 있다. Eureka는 크게 두 가지 구성 요소로 나뉜다.
- Eureka Server: 서비스 레지스트리 역할을 하는 중앙 서버다. 모든 마이크로서비스 인스턴스가 자신의 정보를 등록하고, 클라이언트가 서비스 정보를 조회하는 곳이다.
- Eureka Client: Eureka Server와 통신하여 자신을 등록하고, 다른 서비스의 정보를 조회하는 역할을 하는 클라이언트 라이브러리다. Spring Boot 애플리케이션에 포함되어 실행된다.
2.2. Eureka의 동작 메커니즘
Eureka의 동작 방식을 단계별로 살펴보면 다음과 같다.
- 서비스 등록(Register): Eureka Client는 애플리케이션 시작 시 자신의 서비스 ID, IP 주소, 포트, 건강 상태 등의 메타데이터를 Eureka Server에 등록한다.
- 하트비트(Heartbeat): 등록된 클라이언트는 주기적으로(기본값 30초) Eureka Server에 하트비트를 전송하여 자신이 여전히 살아있음을 알린다. 이를 '갱신(Renew)'이라고도 한다.
- 서비스 조회(Fetch Registry): 클라이언트는 다른 서비스를 호출해야 할 때 Eureka Server에서 서비스 레지스트리 정보를 조회한다. 성능 최적화를 위해 클라이언트는 이 정보를 로컬에 캐싱하고, 주기적으로(기본값 30초) 갱신한다.
- 서비스 제거(Eviction): Eureka Server는 일정 시간(기본값 90초) 동안 하트비트를 받지 못한 인스턴스를 레지스트리에서 제거한다.
- 서비스 종료(Cancel): 클라이언트가 정상적으로 종료될 때는 Eureka Server에 종료 신호를 보내 레지스트리에서 자신을 제거한다.
3. Eureka Server - 프로젝트 생성
3.1. 프로젝트 생성 및 의존성 추가
Eureka Server를 구축하기 위해 먼저 Spring Boot 프로젝트를 생성한다.
build.gradle
plugins {
id 'org.springframework.boot' version '3.2.0'
id 'io.spring.dependency-management' version '1.1.4'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
repositories {
mavenCentral()
}
ext {
set('springCloudVersion', "2023.0.0")
}
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}
3.2. 메인 애플리케이션 클래스
src/main/java/com/example/discoveryservice/DiscoveryServiceApplication.java
package com.example.discoveryservice;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer // Eureka Server 활성화
public class DiscoveryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(DiscoveryServiceApplication.class, args);
}
}
3.3. 애플리케이션 설정
src/main/resources/application.yml
server:
port: 8761
spring:
application:
name: service-discovery
eureka:
client:
register-with-eureka: false # Eureka Server 자신을 클라이언트로 등록하지 않음
fetch-registry: false # 레지스트리 정보를 로컬에 캐싱하지 않음
왜 Eureka 서버와 마이크로서비스 클라이언트의 설정이 다른가?
일반적인 마이크로서비스는 다른 서비스와 상호작용을 해야 하므로 두 설정이 모두 true여야 한다. 반면, Eureka 서버 자체는 등록을 받고 목록을 제공하는 주체이므로, 단일 서버 환경에서는 두 설정이 모두 false가 되는 것이 올바른 구성이다.
| 서비스 역할 | 설정 | 의미 |
| 마이크로서비스 (클라이언트) | register-with-eureka: true | 다른 서비스가 나를 찾을 수 있도록 내 정보를 등록한다. |
| fetch-registry: true | 내가 다른 서비스를 찾을 수 있도록 전체 목록을 가져온다. | |
| Eureka 서버 (단일 구성) | register-with-eureka: false | 스스로가 '안내 데스크'이므로, 자신에게 등록할 필요가 없다. |
| fetch-registry: false | 스스로가 '안내 지도'를 가지고 있으므로, 자신에게 물어볼 필요가 없다. |
3.4. 실행 및 확인
애플리케이션을 실행한 후 웹 브라우저에서 http://localhost:8761에 접속하면 Eureka Server의 대시보드를 확인할 수 있다. 현재는 등록된 서비스가 없으므로 빈 화면이 표시된다.

4. Eureka Client - User Service
4.1. User Service 프로젝트 생성
이제 Eureka Server에 등록할 클라이언트 서비스를 생성한다. 사용자 관리 기능을 담당할 User Service를 만들어보자.
build.gradle
plugins {
id 'org.springframework.boot' version '3.2.0'
id 'io.spring.dependency-management' version '1.1.4'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
repositories {
mavenCentral()
}
ext {
set('springCloudVersion', "2023.0.0")
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
compileOnly 'org.projectlombok:lombok'
developmentOnly 'org.springframework.boot:spring-boot-devtools'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}
4.2. 메인 애플리케이션 클래스
src/main/java/com/example/userservice/UserServiceApplication.java
package com.example.userservice;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient // Eureka Client 활성화
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
}
4.3. 애플리케이션 설정
src/main/resources/application.yml
server:
port: 60000
spring:
application:
name: user-service
eureka:
client:
fetch-registry: true
register-with-eureka: true
service-url:
defaultZone: <http://127.0.0.1:8761/eureka>
4.4. 간단한 REST 컨트롤러 추가
src/main/java/com/example/userservice/controller/UserController.java
package com.example.userservice.controller;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@RestController
@RequestMapping("/users")
public class UserController {
@Value("${server.port}")
private String port;
@Value("${spring.application.name}")
private String serviceName;
@GetMapping("/health")
public Map<String, String> health() {
Map<String, String> response = new HashMap<>();
response.put("service", serviceName);
response.put("port", port);
response.put("status", "UP");
return response;
}
@GetMapping("/welcome")
public String welcome() {
return "Welcome to User Service!";
}
}4.5. 실행

4.6. 확인

5. 멀티 인스턴스 실행과 동적 포트 할당
5.1. 수동 포트 설정의 한계
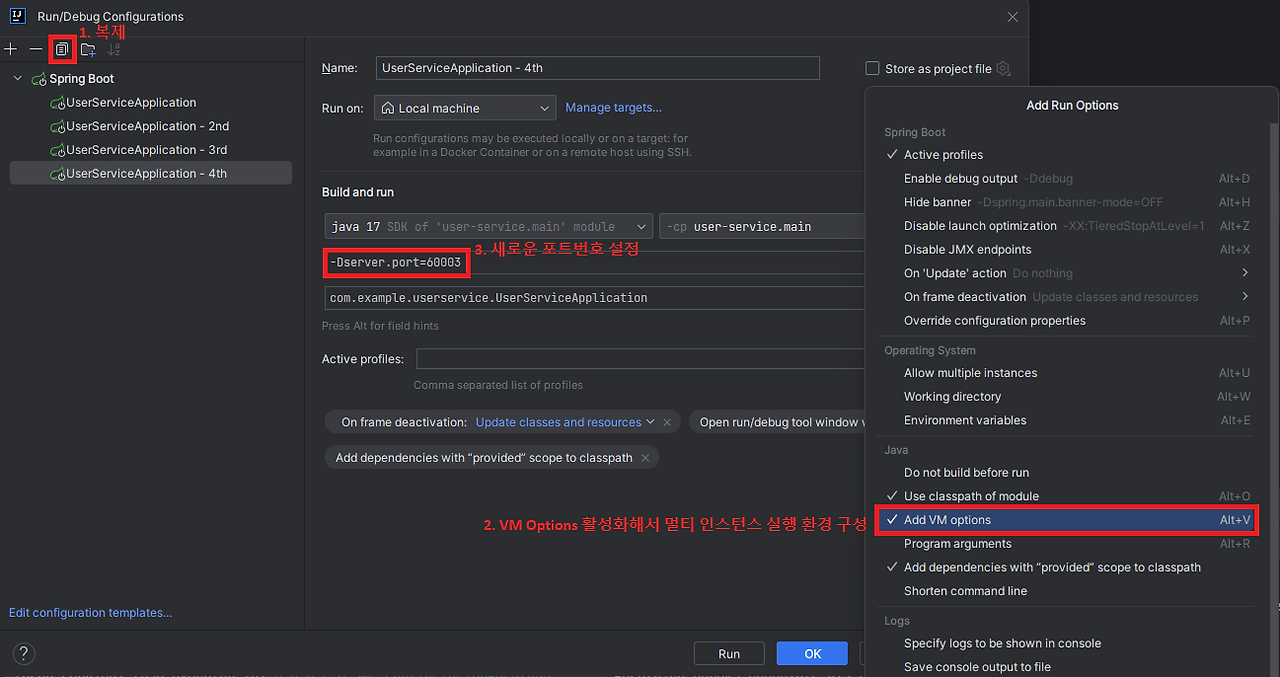
여러 개의 User Service 인스턴스를 실행하려면 어떻게 해야 할까? IntelliJ에서 실행 구성을 복제하여 포트를 60001, 60002로 각각 설정하거나, 터미널에서 -Dserver.port 옵션을 부여하여 실행할 수 있다.
# Gradle 프로젝트의 경우
./gradlew build
java -jar -Dserver.port=60001 build/libs/user-service-0.0.1-SNAPSHOT.jar
java -jar -Dserver.port=60002 build/libs/user-service-0.0.1-SNAPSHOT.jar
하지만 서비스 인스턴스를 추가할 때마다 매번 다른 포트 번호를 직접 할당하는 방식은 매우 번거롭고 비효율적이다. 오토 스케일링 환경에서는 새로운 인스턴스가 자동으로 생성될 때마다 포트를 수동으로 지정할 수 없기 때문이다. 이러한 수동 설정을 자동화하기 위해, 애플리케이션이 시작될 때마다 비어있는 포트를 알아서 사용하도록 하는 랜덤 포트(Random Port) 방식이 필요하다.
5.2. 첫 번째 해결 시도: 랜덤 포트 설정 (port: 0)
Spring Boot에서는 application.yml의 server.port 값을 0으로 설정하면, 애플리케이션 실행 시 사용 가능한 포트를 임의로 할당받아 실행된다.
application.yml 수정
server:
port: 0 # 랜덤 포트 사용
spring:
application:
name: user-service
eureka:
client:
fetch-registry: true
register-with-eureka: true
service-url:
defaultZone: <http://127.0.0.1:8761/eureka>
이 설정을 적용하고 IntelliJ와 터미널에서 각각 인스턴스를 실행하면, 포트 충돌 없이 여러 개의 애플리케이션이 정상적으로 구동되는 것을 로그를 통해 확인할 수 있다. 하지만 Eureka 대시보드를 확인해보면 예상과 다른 결과가 나타난다. 분명 여러 개의 인스턴스를 실행했지만, 아래와 같이 Eureka에는 단 하나의 인스턴스만 등록되어 있다.

왜 이런 현상이 발생할까? 각 인스턴스가 랜덤 포트를 할당받아 충돌 없이 실행되는 것은 맞다. 그러나 Eureka 서버에 자신을 등록할 때 보내는 정보의 기반이 되는 application.yml에는 포트가 0으로 명시되어 있다. Eureka 서버 입장에서는 동일한 서비스 이름(user-service)을 가진 여러 인스턴스가 모두 포트 0으로 등록 요청을 보내는 셈이므로, 이를 하나의 동일한 인스턴스로 인식하고 마지막 요청으로 정보를 덮어쓰게 된다.
5.3. 두 번째 해결 시도: 고유 인스턴스 ID 부여
이 문제를 해결하려면, 각 인스턴스가 Eureka 서버에 등록될 때 서로를 구분할 수 있는 고유한 식별자(ID)를 갖도록 설정해야 한다. eureka.instance.instance-id 속성을 사용하면 이 문제를 해결할 수 있다.
application.yml 재수정
server:
port: 0
spring:
application:
name: user-service
eureka:
instance:
instance-id: ${spring.application.name}:${spring.application.instance_id:${random.value}}
client:
fetch-registry: true
register-with-eureka: true
service-url:
defaultZone: <http://127.0.0.1:8761/eureka>
- eureka.instance.instance-id: Eureka에 등록될 인스턴스의 ID를 정의한다.
- ${spring.application.name}: 서비스 이름 (user-service)
- ${spring.application.instance_id:${random.value}}: Spring Boot에서 인스턴스별로 부여되는 고유 ID. 만약 이 값이 없으면 뒤의 ${random.value}가 임의의 값을 생성하여 사용한다.
결과적으로 user-service:a1b2c3d4e5f6 와 같이 서비스 이름과 랜덤 값이 조합된 고유한 ID가 생성되어 Eureka에 등록된다.
5.4. 실행 및 결과 확인
수정된 application.yml을 적용하고, 다시 IntelliJ와 터미널에서 여러 인스턴스를 실행한다. 이제 Eureka 대시보드를 확인하면, 각 인스턴스가 고유한 ID와 함께 실제 할당받은 랜덤 포트 번호로 정상적으로 등록된 것을 볼 수 있다.

이처럼 동적 포트 할당과 고유 인스턴스 ID 설정을 통해, 수동 개입 없이도 마이크로서비스의 인스턴스를 유연하게 확장할 수 있는 기반이 마련된다. 이는 향후 API 게이트웨이를 통한 동적 라우팅 및 로드 밸런싱의 전제 조건이 된다.
6. 로드 밸런싱 구현
6.1. 클라이언트 사이드 로드 밸런싱의 이해
여러 인스턴스가 실행 중일 때, 클라이언트는 어떻게 적절한 인스턴스를 선택할까? 이때 필요한 것이 로드 밸런싱이다. Spring Cloud는 클라이언트 사이드 로드 밸런싱을 위해 Spring Cloud LoadBalancer를 제공한다. 클라이언트 사이드 로드 밸런싱의 동작 방식은 다음과 같다.
- 클라이언트(호출하는 서비스)는 Eureka Server에서 대상 서비스의 인스턴스 목록을 조회한다.
- Spring Cloud LoadBalancer는 이 목록을 받아 로드 밸런싱 알고리즘(라운드 로빈, 랜덤 등)을 적용하여 하나의 인스턴스를 선택한다.
- 선택된 인스턴스로 요청을 전송한다.
6.2. Order Service 생성 (Feign Client 사용 예시)
User Service를 호출할 Order Service를 생성하여 로드 밸런싱을 테스트해보자.
build.gradle (Order Service)
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
implementation 'org.springframework.cloud:spring-cloud-starter-openfeign'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
}
메인 애플리케이션 클래스
package com.example.orderservice;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}
Feign Client 인터페이스
package com.example.orderservice.client;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.Map;
@FeignClient(name = "user-service") // Eureka에 등록된 서비스 이름
public interface UserServiceClient {
@GetMapping("/users/health")
Map<String, String> getUserServiceHealth();
@GetMapping("/users/welcome")
String getWelcomeMessage();
}REST 컨트롤러
package com.example.orderservice.controller;
import com.example.orderservice.client.UserServiceClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
private UserServiceClient userServiceClient;
@GetMapping("/health")
public Map<String, Object> health() {
Map<String, Object> response = new HashMap<>();
response.put("service", "order-service");
response.put("status", "UP");
// User Service의 상태 확인 (로드 밸런싱 적용됨)
Map<String, String> userServiceHealth = userServiceClient.getUserServiceHealth();
response.put("user-service", userServiceHealth);
return response;
}
@GetMapping("/test-loadbalancer")
public String testLoadBalancer() {
StringBuilder result = new StringBuilder();
for (int i = 0; i < 10; i++) {
result.append("호출 ").append(i+1).append(": ")
.append(userServiceClient.getWelcomeMessage())
.append("\\n");
}
return result.toString();
}
}6.3. 실행 및 테스트
- Eureka Server 실행
- User Service를 2개 이상의 인스턴스로 실행 (예: 60001, 60002 포트)
- Order Service 실행
- 브라우저에서 http://localhost:{order-service-port}/orders/test-loadbalancer 접속
여러 번의 호출이 각기 다른 User Service 인스턴스로 분산되어 전달되는 것을 확인할 수 있다.
7. Eureka의 한계와 현업 활용
7.1. Eureka의 한계점
Eureka는 널리 사용되는 서비스 디스커버리 도구이지만, 몇 가지 한계점이 존재한다.
- Java 중심 생태계: Eureka Client는 Java 라이브러리 형태로 제공되므로, 폴리글랏 환경에서는 각 언어별로 클라이언트를 별도로 구현해야 하는 어려움이 있다.
- 운영 부담: Eureka Server를 자체적으로 구축하고 고가용성으로 운영하려면 추가적인 인프라 관리 부담이 발생한다.
- 기능의 제한: 서비스 디스커버리 외에 상태 확인이나 구성 관리 등의 추가 기능은 제공하지 않는다.
- 자가 보존 모드의 복잡성: 네트워크 파티션 상황에서 자가 보존 모드의 동작 방식에 대한 이해가 필요하며, 잘못 설정할 경우 문제가 발생할 수 있다.
7.2. 쿠버네티스 환경에서의 서비스 디스커버리
쿠버네티스(Kubernetes) 환경에서는 Eureka 없이도 기본적으로 서비스 디스커버리 기능을 제공한다.
- Kube-DNS/CoreDNS: 쿠버네티스는 DNS 기반의 서비스 디스커버리를 제공한다. 서비스 이름으로 DNS 질의를 하면 해당 서비스의 Cluster IP(가상 IP)를 반환한다.
- Kube-proxy: 각 노드에서 실행되는 Kube-proxy는 서비스에 대한 요청을 실제 파드(Pod)로 전달하는 역할을 한다. iptables나 IPVS 규칙을 동적으로 업데이트하여 로드 밸런싱을 수행한다.
- Headless Service: 특별한 설정을 통해 DNS 라운드 로빈을 사용하거나, 각 파드의 개별 IP 주소를 조회할 수도 있다.
- 쿠버네티스의 장점: 별도의 서비스 디스커버리 인프라를 구축할 필요 없이, 쿠버네티스 플랫폼 자체가 제공하는 기능을 활용할 수 있다. 또한 모든 언어와 프레임워크에서 표준 DNS를 통해 접근할 수 있어 폴리글랏 환경에 적합하다.
7.3. Eureka와 쿠버네티스의 선택 기준
실무에서 Eureka를 선택할지, 쿠버네티스의 내장 서비스 디스커버리를 사용할지는 다음과 같은 기준으로 결정할 수 있다.
Eureka가 더 적합한 경우:
- 쿠버네티스 외부에서 실행되는 레거시 시스템과의 통합이 필요한 경우
- 애플리케이션 레벨에서 더 세밀한 라우팅 규칙이나 메타데이터 기반 필터링이 필요한 경우
- 쿠버네티스로의 완전한 이전이 아직 진행 중인 과도기 단계
- AWS EC2 등 VM 기반 인프라에서 운영 중인 경우
쿠버네티스가 더 적합한 경우:
- 이미 쿠버네티스 플랫폼 위에서 모든 애플리케이션이 운영되는 경우
- 폴리글랏 환경(다양한 프로그래밍 언어 사용)
- 운영 인프라를 최소화하고 플랫폼의 표준 기능을 최대한 활용하려는 경우
- 서비스 메시(Istio, Linkerd 등)와의 통합을 고려하는 경우
7.4. 다른 서비스 디스커버리 대체제
Eureka 외에도 다양한 서비스 디스커버리 도구가 존재한다.
HashiCorp Consul:
- 서비스 디스커버리 외에도 건강 상태 확인, 키-값 저장소, 다중 데이터센터 지원 등 풍부한 기능 제공
- DNS와 HTTP API를 모두 지원하여 폴리글랏 환경에 적합
- 서비스 메시 기능도 통합 제공
Apache ZooKeeper:
- 분산 코디네이션 서비스로, 서비스 디스커버리에도 활용 가능
- Kafka, Hadoop 등 빅데이터 생태계와의 통합에 강점
- CP 시스템(일관성 우선)으로 네트워크 파티션 시 일관성 유지
etcd:
- CoreOS에서 개발한 분산 키-값 저장소
- Kubernetes의 기반 저장소로 사용됨
- 간단하고 안정적이며, gRPC 기반 통신
Nacos:
- Alibaba에서 개발한 서비스 디스커버리 및 설정 관리 플랫폼
- Spring Cloud Alibaba와의 통합 용이
- 동적 설정 관리 기능도 통합 제공
7.5. 실무에서의 표준과 Best Practice
현업에서의 서비스 디스커버리 선택과 운영에 관한 모범 사례를 살펴보자.
- 신규 프로젝트의 경우: 쿠버네티스 기반 신규 프로젝트라면, 대부분의 팀은 Eureka 대신 쿠버네티스의 내장 서비스 디스커버리를 사용한다. 인프라 플랫폼이 제공하는 표준 기능을 활용함으로써 운영 부담을 줄이고 생태계의 일관성을 유지할 수 있다.
- 점진적 이전이 필요한 경우: 레거시 시스템을 점진적으로 마이크로서비스로 전환하는 과정에서는 Eureka가 유용할 수 있다. VM 환경과 컨테이너 환경이 혼재된 과도기에는 Eureka가 중립적인 서비스 레지스트리 역할을 할 수 있다.
- 멀티 클라우드 또는 하이브리드 클라우드: 여러 클라우드 제공업체나 온프레미스 환경을 함께 운영하는 경우, Consul과 같은 플랫폼 중립적인 도구를 선택하는 것이 좋다. Consul은 다양한 환경에 걸쳐 일관된 서비스 디스커버리를 제공한다.
운영 모범 사례:
- 고가용성 구성: Eureka Server는 최소 3개 이상의 인스턴스로 클러스터링하여 운영한다. 피어 간 복제를 통해 서로의 정보를 동기화한다.
- 네트워크 분리: Eureka Server는 내부 네트워크에 위치시키고, 외부에서 직접 접근하지 못하도록 구성한다.
- 모니터링과 알림: Eureka Server의 상태, 등록된 서비스 수, 자가 보존 모드 활성화 여부 등을 모니터링하고, 이상 징후 시 알림을 받을 수 있도록 설정한다.
- 설정 최적화: 환경에 맞게 하트비트 주기, 만료 시간, 자가 보존 모드 등을 적절히 튜닝한다.
- 보안 적용: Eureka Server에 접근 제어와 TLS 암호화를 적용하여 보안을 강화한다.
Eureka Server 클러스터링 예시:
# application-peer1.yml
spring:
application:
name: discoveryservice
eureka:
client:
service-url:
defaultZone: <http://peer2:8762/eureka/,http://peer3:8763/eureka/>
server:
enable-self-preservation: true # 프로덕션에서는 활성화
# application-peer2.yml (유사한 설정)
eureka:
client:
service-url:
defaultZone: <http://peer1:8761/eureka/,http://peer3:8763/eureka/>
7.6. 결론: 언제 무엇을 선택할 것인가?
서비스 디스커버리 도구 선택은 결국 팀의 상황과 요구사항에 달려 있다.
Eureka를 선택해야 하는 경우:
- Spring 생태계에 이미 투자되어 있고 Java 기반 개발이 주를 이루는 경우
- VM 기반 인프라에서 운영 중이며, 쿠버네티스 도입 계획이 당장 없는 경우
- 클라이언트 사이드 디스커버리 패턴이 더 적합한 아키텍처를 가진 경우
쿠버네티스 내장 기능을 사용해야 하는 경우:
- 이미 쿠버네티스에 애플리케이션을 배포하고 있는 경우
- 플랫폼이 제공하는 표준 기능을 최대한 활용하여 운영 복잡도를 줄이고 싶은 경우
- 멀티 언어 환경에서 개발하는 경우
Consul이나 다른 도구를 고려해야 하는 경우:
- 멀티 클라우드 또는 하이브리드 클라우드 환경인 경우
- 서비스 디스커버리 외에도 헬스 체킹, 설정 관리, 서비스 메시 등 통합 솔루션이 필요한 경우
결론적으로, 현대 클라우드 네이티브 환경에서는 쿠버네티스의 내장 서비스 디스커버리를 기본으로 선택하고, 특별한 요구사항이 있을 때 Eureka나 다른 도구를 추가하는 추세다. 그러나 기존 레거시 시스템과의 통합이나 점진적 전환 과정에서는 여전히 Eureka가 유효한 선택지이며, Spring Cloud 생태계와의 완벽한 통합은 개발 생산성 측면에서 큰 장점을 제공한다.
중요한 것은 특정 기술에 집착하기보다, 팀의 상황과 요구사항에 가장 적합한 도구를 선택하는 유연함이다. 또한 어떤 도구를 선택하든, 고가용성, 모니터링, 보안 등 운영 측면의 모범 사례를 따르는 것이 안정적인 마이크로서비스 운영의 핵심이다.
'MSA > MSA 기본' 카테고리의 다른 글
| [BASIC #6] Configuration Service와 중앙 설정 관리 (0) | 2025.09.20 |
|---|---|
| [BASIC #5] 인증 처리와 JWT 기반 보안 (0) | 2025.09.20 |
| [BASIC #4][실습] E-commerce MSA 프로젝트 구조 설계 (0) | 2025.09.20 |
| [BASIC #3] API Gateway (0) | 2025.09.20 |
| [BASIC #1] Microservice와 Spring Cloud의 소개 (0) | 2025.09.20 |