
1. 로컬 캐싱의 기본 개념
백엔드 성능 최적화를 위한 캐싱 전략 중 가장 기초적이면서도 강력한 방법은 로컬 캐싱(Local Caching)이다. 로컬 캐싱이란 애플리케이션 서버가 구동되는 자신의 메모리 공간(RAM)에 데이터를 직접 저장하여 활용하는 방식을 의미한다.
데이터베이스나 외부 저장소를 거치지 않고, 서버 내부의 힙(Heap) 메모리 영역 등에 데이터를 적재해 두었다가 필요할 때 즉시 꺼내 쓰는 구조이다. 이는 별도의 인프라 구축 없이도 코드 수준에서 즉각적인 성능 향상을 도출할 수 있는 가장 효율적인 수단 중 하나로 평가받는다.
2. 로컬 캐싱의 주요 장점
로컬 캐싱은 외부 시스템에 의존하지 않는 특성 덕분에 다음과 같은 독보적인 이점을 제공한다.
- 압도적인 접근 속도: 네트워크 통신(Network I/O) 과정이 전혀 필요하지 않다. 메모리 내에서 객체를 참조하는 수준의 연산만 수행되므로 리모트 캐시(Remote Cache)에 비해 응답 시간이 극도로 짧다.
- 인프라 복잡도 감소: Redis나 Memcached와 같은 별도의 캐시 서버를 구축하거나 관리할 필요가 없다. 서버 애플리케이션의 메모리만을 활용하기 때문에 초기 개발 및 운영 비용이 저렴하다.
- 외부 장애에 대한 독립성: 외부 캐시 시스템이나 데이터베이스 네트워크에 일시적인 장애가 발생하더라도, 로컬 캐시에 저장된 데이터는 안정적으로 조회할 수 있다. 이는 시스템의 가용성(Availability)을 높이는 데 기여한다.
3. 로컬 캐싱 vs 리모트 캐싱 구조 분석
로컬 캐싱과 리모트 캐싱은 데이터가 저장되는 위치와 공유 방식에 따라 명확한 차이를 보인다.
3.1. 로컬 캐싱 (Local Caching)
각 서버 인스턴스가 독립적인 캐시 공간을 가진다.
- 흐름: 요청 → 서버 인스턴스 → 해당 서버의 로컬 메모리 → (Miss 시) DB 조회
- 특징: 서버 간 캐시 데이터가 공유되지 않으며, 서버별로 데이터 불일치(Inconsistency)가 발생할 수 있다.
3.2. 리모트 캐싱 (Remote Caching)
여러 서버가 공용 캐시 서버(예: Redis)를 공유한다.
- 흐름: 요청 → 서버 인스턴스 → 외부 공용 캐시 → (Miss 시) DB 조회
- 특징: 모든 서버가 동일한 데이터를 바라보므로 데이터 정합성 유지에 유리하지만, 네트워크 통신 비용이 발생한다.
4. 로컬 캐싱이 적합한 시나리오
로컬 캐싱은 모든 상황에 만능은 아니며, 데이터의 성격에 따라 전략적으로 적용해야 한다. 특히 다음과 같은 상황에서 가장 높은 효율을 발휘한다.
- 변경 빈도가 극히 낮은 공통 데이터: 국가별 공휴일 목록, 서비스의 환경 설정 값, 공통 코드(Common Code) 등 전 국민이나 모든 시스템이 동일하게 사용하며 자주 바뀌지 않는 데이터는 로컬 캐싱의 최적 대상이다.
- 사용자별로 차별화되지 않는 데이터: 특정 사용자 ID에 종속되지 않고 모든 요청에서 범용적으로 사용되는 데이터일수록 로컬 캐시의 히트율(Hit Ratio)이 높아진다.
- 서버 간 데이터 불일치가 치명적이지 않은 경우: 로컬 캐싱은 서버마다 데이터 만료 시점이 약간씩 다를 수 있다. 만약 1~2초 정도의 데이터 차이가 비즈니스 로직에 큰 영향을 주지 않는다면 로컬 캐싱을 적극적으로 권장한다.
5. Spring Cache Abstraction: 캐시 추상화의 이해
백엔드 시스템에서 로컬 캐싱을 효율적으로 관리하기 위해 Spring은 Cache Abstraction(캐시 추상화) 기능을 제공한다. 이는 개발자가 캐시의 세부 구현 기술(ConcurrentMap, Redis, Caffeine 등)에 종속되지 않고, 어노테이션 기반으로 선언적 캐싱을 적용할 수 있게 돕는다.
핵심 원칙: 개발자는 "무엇을 캐싱할 것인가?"라는 비즈니스 로직에만 집중하며, "어떻게 캐싱할 것인가?"에 대한 메커니즘은 Spring 프레임워크가 담당한다.
5.1. 동작 원리: 프록시 기반 AOP
Spring의 캐시 추상화는 내부적으로 프록시 기반의 AOP(Aspect Oriented Programming) 방식으로 동작한다. 특정 메서드에 캐시 어노테이션을 부착하면, Spring은 해당 빈(Bean)을 프록시 객체로 감싸서 호출을 가로챈다.
5.2. 주요 어노테이션의 기능
선언적 캐싱을 위해 주로 사용되는 세 가지 어노테이션은 다음과 같다.
- @Cacheable: 메서드 실행 전 캐시를 조회한다. 데이터가 있으면 즉시 반환하고, 없으면 메서드 실행 후 결과를 캐시에 저장한다.
- @CacheEvict: 데이터의 변경이 발생했을 때 관련 캐시를 제거하여 데이터 정합성을 유지한다.
- @CachePut: 메서드를 항상 실행하며, 그 결과를 캐시에 업데이트한다.
6. 캐시 시스템의 내부 구성 요소
캐시 추상화가 정상적으로 작동하기 위해 내부적으로 협력하는 핵심 컴포넌트들은 다음과 같다.
- CacheManager: 캐시 저장소를 관리하고 조율하는 중추적인 인터페이스이다.
- Cache: 실제 데이터가 저장되는 물리적인 공간이다.
- CacheInterceptor: 캐시 어노테이션을 해석하여 프록시 로직을 실행하는 인터페이스이다.
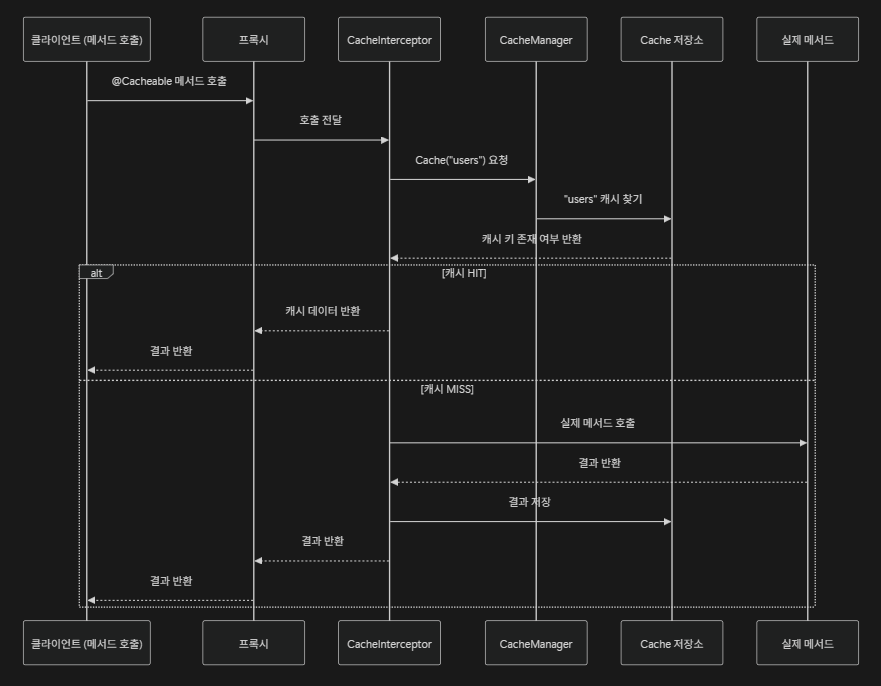
6.1. 캐시 처리 프로세스 (Sequence Diagram)
클라이언트가 캐싱된 메서드를 호출할 때의 상세 흐름은 아래와 같다.
- 호출 가로채기: 프록시 객체가 클라이언트의 메서드 호출을 가로챈다.
- 어노테이션 해석: CacheInterceptor가 설정된 캐시 이름과 키를 확인한다.
- 캐시 조회: CacheManager를 통해 해당 명칭의 Cache 저장소에서 데이터를 조회한다.
- HIT / MISS 처리:
- HIT: 저장된 데이터를 즉시 반환한다.
- MISS: 실제 메서드(TargetMethod)를 실행하고 그 결과를 캐시에 저장한 뒤 반환한다.
7. 캐시 기능의 핵심 조율자: CacheManager
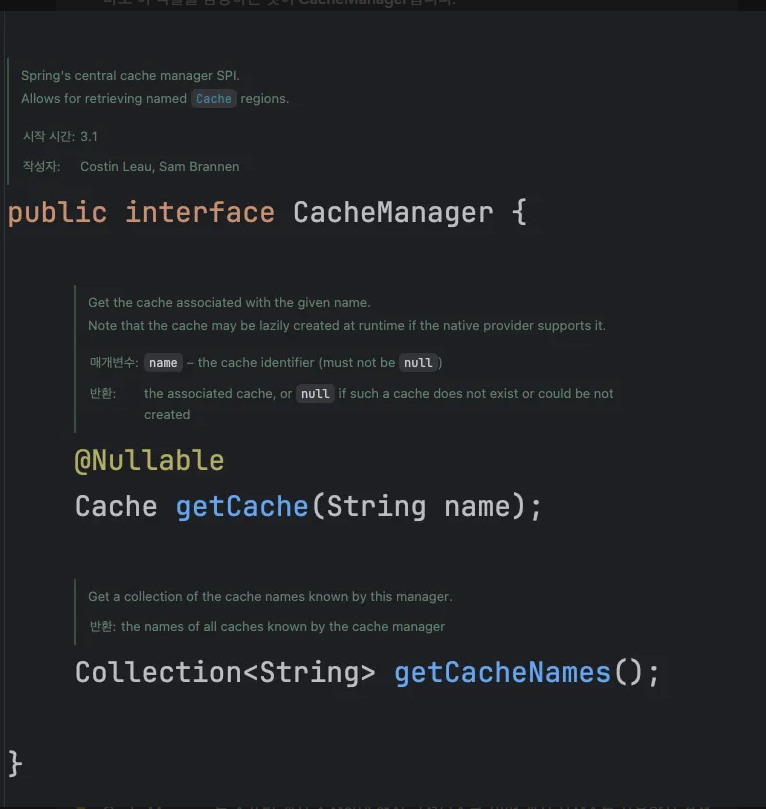
CacheManager는 어떤 캐시 구현체를 사용할지 결정하고, 메서드 호출을 실제 저장소로 연결해 주는 역할을 수행한다. 예를 들어, @Cacheable(value="users")와 같이 선언하면 Spring은 CacheManager에게 "users"라는 이름의 캐시 저장소를 요청한다. 결국 CacheManager가 존재하기에 다양한 캐시 구현체를 유연하게 교체하며 사용할 수 있는 것이다.
8. 캐시 키 생성 기준: SimpleKeyGenerator
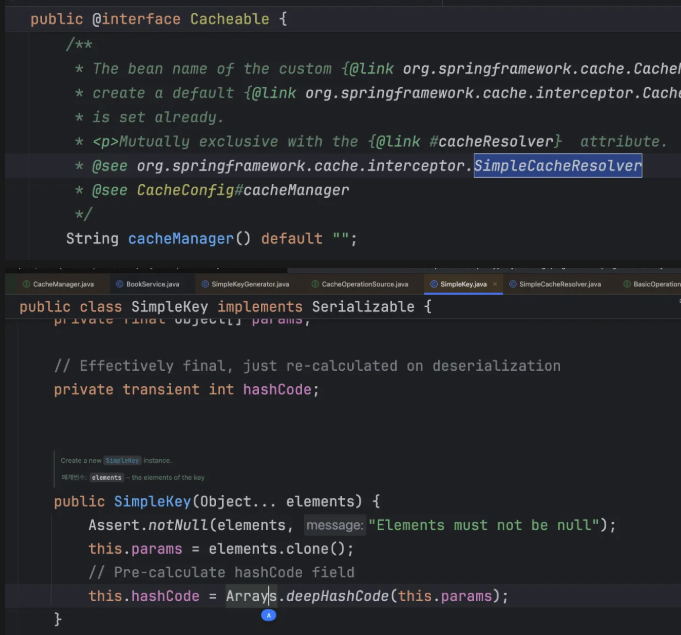
저장소를 선택한 이후에는 데이터를 식별할 캐시 키(Cache Key)를 생성해야 한다. Spring은 기본적으로 SimpleKeyGenerator를 사용한다.
- 생성 원리: 메서드에 전달되는 모든 파라미터 값을 조합하여 키를 만든다.
- 주의 사항: 내부적으로 equals()와 hashCode()를 기반으로 키를 비교하므로, 파라미터로 전달되는 객체는 이 두 메서드가 올바르게 오버라이드되어 있어야 한다.
9. 기본 로컬 캐시: ConcurrentMapCacheManager
별도의 캐시 라이브러리를 추가하지 않을 경우, Spring Boot는 기본적으로 ConcurrentMapCacheManager를 로컬 캐시 구현체로 활용한다.
이 구현체는 내부적으로 Java의 ConcurrentHashMap을 저장소로 사용한다. 이는 멀티스레드 환경에서 원자성을 보장하며 매우 빠른 속도를 제공하므로, 단일 서버 환경에서 성능을 최적화하는 데 매우 효율적이다.
10. @Cacheable을 활용한 로컬 캐싱 실습
Spring Cache Abstraction이 제공하는 강력한 기능을 활용하면 복잡한 캐싱 로직을 단 몇 줄의 어노테이션으로 대체할 수 있다.
10.1. 캐싱 활성화 및 설정
Spring Boot에서 캐싱 기능을 사용하기 위해서는 먼저 @EnableCaching 어노테이션을 통해 기능을 활성화해야 한다. 기본적으로는 ConcurrentMapCacheManager가 자동 등록되지만, 향후 Redis와 같은 외부 저장소를 연동할 경우 자동 설정이 해제될 수 있으므로 아래와 같이 명시적으로 Bean을 등록하는 것이 권장된다.
@EnableCaching
@Configuration
public class LocalCacheConfig {
@Bean
public CacheManager cacheManager() {
// 명시적으로 로컬 캐시 매니저를 등록하여 Redis 설정과 공존할 수 있도록 함
return new ConcurrentMapCacheManager();
}
}10.2. 도메인 모델 정의
실습에 사용할 간단한 도서 관리 도메인이다. 데이터베이스와의 상동성을 보장하기 위해 JPA 엔티티로 구성하였다.
@ToString
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(name = "ch6_book")
@Entity
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private boolean isSoldOut;
}11. @Cacheable의 기본 동작 원리
@Cacheable 어노테이션은 메서드가 호출될 때 다음과 같은 내부 프로세스를 거친다. 이는 CacheAspectSupport 클래스 내 로직을 통해 구현된다.
- 조회: 메서드 호출 시 지정된 캐시 저장소(value)에서 동일한 키가 존재하는지 확인한다.
- 적중(HIT): 캐시에 데이터가 존재하면 메서드 본문을 실행하지 않고 캐시된 값을 즉시 반환한다.
- 미적중(MISS): 캐시에 데이터가 없으면 실제 메서드를 실행하고, 그 결과를 캐시에 저장한 뒤 반환한다.
11.1. 기초 적용 및 검증
가장 기본적인 형태로 ID를 통한 도서 조회 메서드에 캐시를 적용해본다.
/**
* - id 를 통해 Book 객체를 로컬 캐싱함
*/
@Cacheable(value = "book")
public Book findBookById(Long id) {
log.info("findBookById 메서드가 실제 실행됩니다.");
return bookRepository.findById(id).orElseThrow();
}이를 테스트 코드로 검증하면 다음과 같은 결과를 얻을 수 있다.
@DisplayName("캐시 적용 테스트")
@Test
void cacheTest() {
Long bookId = book.getId();
// 첫 번째 호출: MISS (메서드 실행 및 로그 출력)
bookService.findBookById(bookId);
// 두 번째 호출: HIT (캐시 데이터 반환, 로그 출력 없음)
bookService.findBookById(bookId);
}12. 상세 활용 전략: 이름과 키의 제어
12.1. 캐시 이름(Value)의 분리
동일한 파라미터를 사용하더라도 메서드의 목적이나 반환 값이 다르다면 캐시 저장소의 이름(value)을 분리해야 한다. 이를 통해 데이터 충돌을 방지하고 독립적인 만료 정책을 적용할 수 있다.
@Cacheable("book")
public Book findBookById(Long id) {
log.info("findBookById 가 실행됩니다.");
return bookRepository.findById(id).orElseThrow();
}
@Cacheable(value = "bookName")
public Book findBookNameById(Long id) {
log.info("findBookNameById 가 실행됩니다.");
return bookRepository.findById(id).orElse(null);
}위와 같이 구성할 경우, 동일한 id 값을 전달하더라도 book과 bookName이라는 서로 다른 저장소에 캐싱되므로 각각 한 번씩 메서드가 호출된다.
12.2. 특정 파라미터를 활용한 캐시 키 설정
Spring은 기본적으로 모든 파라미터를 조합해 키를 생성한다. 하지만 특정 값만을 키로 사용하고 싶을 때는 key 속성을 활용할 수 있다. 이는 SpEL(Spring Expression Language)을 기반으로 동작한다.
/**
* - id와 name을 모두 받지만, id 값만 캐시 키로 사용함
*/
@Cacheable(value = "bookIdAndName", key = "#id")
public Book findBookByIdAndName(Long id, String name) {
log.info("findBookByIdAndName 가 실행됩니다.");
return bookRepository.findByIdAndName(id, name).orElseThrow();
}13. 로컬 캐싱의 한계와 주의사항
로컬 캐싱은 매우 빠르고 간편하지만, 엔터프라이즈 환경의 대규모 시스템에서는 다음과 같은 명확한 한계점을 지닌다.
- 데이터 불일치 (Inconsistency): 서버가 다중화(Scale-out)된 환경에서 각 인스턴스는 각기 다른 메모리 공간을 가진다. 1번 서버에서 캐시가 갱신되어도 2번 서버는 과거 데이터를 들고 있을 위험이 있다.
- 휘발성: 애플리케이션 서버가 재시작되면 메모리에 저장된 모든 캐시 데이터가 소실된다.
- 메모리 압박: 서버 자체의 Heap 메모리를 사용하므로, 캐시 데이터가 비대해질 경우 가비지 컬렉션(GC) 빈도가 높아져 전반적인 서버 성능 저하를 초래할 수 있다.
'Database > Redis' 카테고리의 다른 글
| [Optimization-6] Remote 캐싱의 이해와 실무 기초 (0) | 2025.12.28 |
|---|---|
| [Optimization-5] Remote 캐싱의 필요성 (0) | 2025.12.28 |
| [Optimization-3] 캐싱 개념(3) (0) | 2025.12.28 |
| [Optimization-2] 캐싱 개념 (2) (0) | 2025.12.28 |
| [Optimization-1] 캐싱 개념(1) (0) | 2025.12.28 |