0. 사전지식
현대 애플리케이션은 트래픽 변화에 유연하게 대응해야 한다. 사용자가 몰리는 시간대에는 자원을 더 많이 사용하고, 한가한 시간에는 줄이는 것이 효율적이다. Kubernetes는 이러한 상황에 대응하기 위한 자동 확장(Autoscaling) 기능을 제공한다.
1. 📌 Kubernetes Autoscaling이란?
Autoscaling은 Kubernetes 클러스터가 워크로드의 부하에 따라 자원을 자동으로 조절하는 기능이다. 수요에 맞게 애플리케이션의 리소스(파드, 노드, 리소스 크기)를 조절하여 다음과 같은 이점을 얻을 수 있다.
1. 애플리케이션의 가용성 향상
2. 클러스터 자원 효율성 증가
3. 수작업 없이 자동으로 스케일 아웃 / 인
예를 들어 CPU 부하가 높아지면 컨테이너 수를 자동으로 늘려서 부하를 분산시키고, 부하가 줄면 다시 줄여준다.
2. 📂 Kubernetes Autoscaler 종류
Kubernetes에서는 다양한 레벨에서 Autoscaling 기능을 제공한다. 크게 HPA, VPA, CA로 분류할 수 있으며 각 기능과 설명에 대한 표는 아래와 같다.
| Autoscaler 종류 | 기능 | 설명 |
| HPA (Horizontal Pod Autoscaler) | 파드 수 조절 | CPU나 메모리 부하에 따라 파드 수를 자동으로 확장 또는 축소 |
| VPA (Vertical Pod Autoscaler) | 리소스 크기 조절 | 파드의 CPU / 메모리 요청/제한 값을 자동으로 조정 |
| CA (Cluster Autoscaler) | 노드 수 조절 | 클러스터의 노드 개수를 자동으로 조절 (클라우드 환경에서 주로 사용) |
VPA에는 사용 시 파드가 종료되기 때문에 온프레미스나 클라우드 환경 모두에서 잘 사용하지 않는다. 온프레미스에서는 HPA를 사용하자.
3. 🔧 VPA (Vertical Pod Autoscaler)

VPA는 말 그대로 Pod의 리소스(CPU, 메모리) 크기를 수직적으로 조절해주는 오토스케일러이다. 트래픽이 증가하면 Pod 자체의 리소스를 더 크게 할당하고, 트래픽이 감소하면 다시 줄인다.
📌항상 고정된 수의 Pod가 필요한 작업 혹은 Pod 수를 늘리는 것이 오히려 성능 저하를 유발하는 작업에 적합
3.1. 설치 및 확인
[1] VPA 작동할 디렉터리 생성
mkdir -p autoscaler/vpa
[2] 다운로드 및 실행 설치
git clone https://github.com/kubernetes/autoscaler.git
cd autoscaler/vertical-pod-autoscaler
[3] VPA 실행
./hack/vpa-down.sh
./hack/vpa-up.sh
[4] 확인
kubectl get pod -n kube-system | grep vpa
3.2. 구조
+---------------------+
| VPA Updater |
+---------------------+
|
v
+---------------------+
| VPA Recommender |
+---------------------+
|
v
+-------------------------+
| VPA Admission Webhook |
+-------------------------+
|
v
(Pod 재시작 및 리소스 반영)
3.3. 요소
3.3.1. VPA Recommender
- 역할: 각 Pod의 실제 리소스 사용량(예: CPU, 메모리)을 수집하여, 적절한 리소스 크기를 계산해 추천
- 동작 방식:
- Metrics Server로부터 수집한 과거 및 현재 리소스 사용량을 바탕으로 분석
- 최소 필요 리소스, 평균 사용량, 최대 예상치를 기반으로 Target 리소스 값을 계산
- 이 추천 값은 VPA에 전달되어 Updater가 참고
3.3.2. VPA Updater
- 역할: 현재 실행 중인 Pod의 리소스 요청값이 Recommender가 제시한 값과 얼마나 차이 나는지를 주기적으로 점검
- 동작 방식:
- 약 1분 간격으로 검사
- 만약 현재 리소스 설정이 추천값과 크게 차이 날 경우, 해당 Pod를 Evict(퇴출)
- 퇴출된 Pod는 재시작되고, 이때 Admission Webhook을 통해 새로운 리소스 값으로 설정
3.3.3. VPA Admission Webhook
- 역할: 새롭게 생성되는 Pod의 리소스 요청값을 자동으로 수정
- 동작 방식:
- Pod가 생성되기 전에 개입하여, VPA Recommender가 제시한 값으로 리소스를 설정
- 이는 K8s의 Mutating Admission Webhook 기능을 통해 이뤄짐
🔄 이 세 요소는 서로 유기적으로 연결되어, 자동 리소스 조정 → Pod 재시작 → 리소스 재설정의 순환 구조를 형성
3.4. 실습 : 부하를 통한 리소스 증가 테스트
이번 실습에서는 hamster라는 Pod를 생성하고, while 루프를 통해 의도적으로 CPU 부하를 주어 VPA가 리소스를 자동으로 늘려가는 과정을 살펴보자.
[1] hamster.yaml 파일 확인
pod 리소스를 100으로 지정해놨는데 while true 때문에 리소스를 계속 사용해서 리소스 부족해지게 되고 더 높은 사양을 요구하게 된다. 결국 위에서 설정한 VPA에 의해 레코멘더가 현재 값(100)이랑 필요로 하는 값(300)을 계산해서 VPA한테 넘겨주고 업데이터가 파드 종료 시킨 뒤에 어드미션 컨트롤러가 100이었던것을 300으로 늘려주고 생성한다. (while문이라서 시간이 지나면 결국 300도 부족해져서 VPA에 무한으로수행된다.)
vi examples/hamster.yaml---
apiVersion: "autoscaling.k8s.io/v1"
kind: VerticalPodAutoscaler
metadata:
name: hamster-vpa
spec:
# recommenders field can be unset when using the default recommender.
# When using an alternative recommender, the alternative recommender's name
# can be specified as the following in a list.
# recommenders:
# - name: 'alternative'
targetRef: # policy를 적용받은 대상
apiVersion: "apps/v1"
kind: Deployment
name: hamster
resourcePolicy: # 자원에 대한 허용 가능 최대/최소 value를 지정
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
---
apiVersion: "autoscaling.k8s.io/v1"
kind: VerticalPodAutoscaler
metadata:
name: hamster-vpa
spec:
# recommenders field can be unset when using the default recommender.
# When using an alternative recommender, the alternative recommender's name
# can be specified as the following in a list.
# recommenders:
# - name: 'alternative'
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: hamster
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
metadata:
labels:
app: hamster
spec:
securityContext:
runAsNonRoot: true
runAsUser: 65534 # nobody
containers:
- name: hamster
image: registry.k8s.io/ubuntu-slim:0.1
resources:
requests:
cpu: 100m
memory: 50Mi
command: ["/bin/sh"]
args:
- "-c"
- "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done"✅ hamster.yaml 주요 정보
[1] VPA 설정
[2] 실제 hamster Pod 스펙 (초기 리소스는 CPU 100m, 메모리 50Mi로 설정)
📌 Pod는 yes 명령어를 통해 CPU를 지속적으로 사용하는 부하를 발생시킨다.
3.4.2. 리소스 생성 및 확인
kubectl apply-f examples/hamster.yamlkubectl describe vpa hamster-vpa
# 아래 사항 확인 가능
# ㄴ [1] Lower Bound : 리소스 사용량 하한값
# ㄴ [2] Target : 목표값
# ㄴ [3] Upcapped Target : 제한 없는 상태 목표값
# ㄴ [4] Upper Bound : 리소스 사용량 상한값
3.4.3. 새로운 터미널에서 정책 확인
# [새로운 터미널 : k8s-master]
kubectl get vpa -A -w | grep hamster
3.4.4. Deep Describe (리소스 값 추적)
# *Deep Describe
sudo apt install jq
## jq : JSON 형식의 테이터 처리를 위한 CLI 기반 프로그램
# 리소스, 정책 확인
kubectl get deploy/hamster -o jsonpath='{.spec.template.spec.containers[*].resources}' | jq
kubectl get vpa hamster-vpa -o jsonpath='{.spec}' | jq
# 추천 리소스 확인
kubectl get vpa hamster-vpa -o jsonpath='{.status.recommendation}' | jq
kubectl get pod -l app=hamster -o jsonpath='{.items[*].spec.containers[*].resources}' | jq
# [새로운 터미널 : k8s-master]
kubectl get events --sort-by="lastTimestamp"
kubectl get vpa hamster-vpa -o jsonpath='{.spec}' | jq
kubectl get vpa hamster-vpa -o jsonpath='{.status.recommendation}' | jq
kubectl get pod -l app=hamster -o jsonpath='{.items[*].spec.containers[*].resources}' | jq
kubectl get pod -l app=hamster -o jsonpath='{.items[*].metadata.annotations}' | jq
4.🔧 HPA
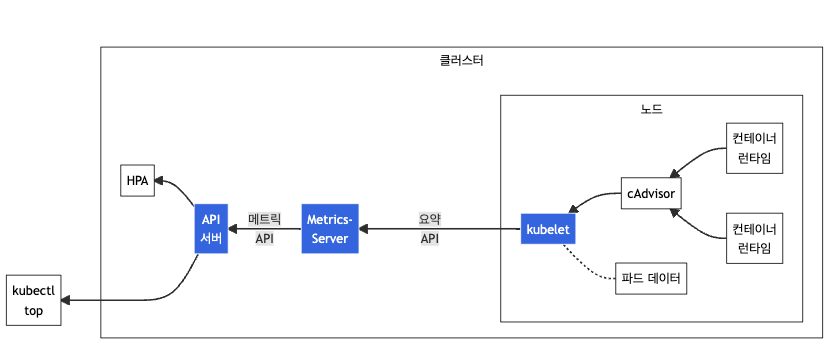
Horizontal Pod Autoscaler(HPA)는 CPU나 메모리 사용량 등의 메트릭을 기준으로 Pod의 수를 자동으로 조절한다. 부하가 증가하면 Pod 수를 늘리고, 감소하면 줄여서 자원을 효율적으로 사용할 수 있도록 한다. 쉽게말해 워크로드의 크기를 수요에 맞게 자동으로 스케일링하는 방식이다.
4.1. 동작 원리
[1] Metrics Server 설치 필요
HPA는 리소스 사용량을 확인하기 위해 Metrics Server라는 컴포넌트를 이용. (위에서 이미 설치 완료)
[2] HPA가 주기적으로 API 서버에 메트릭 요청
HPA 컨트롤러는 주기적으로 쿠버네티스 API 서버에 현재 리소스 사용량 정보를 요청.
[3] API 서버가 Metrics Server에 메트릭 요청
API 서버는 Metrics Server에 요청을 전달.
[4] Metrics Server는 각 노드의 kubelet에서 메트릭 수집
Metrics Server는 각 워커 노드에 있는 kubelet으로부터 메트릭 정보를 받아옴.
[5] kubelet → cAdvisor를 통해 컨테이너 리소스 수집
kubelet 내부에는 cAdvisor라는 데몬이 있는데, 이 도구가 실제 컨테이너의 CPU, 메모리 등의 사용량을 수집.
[6] HPA가 수집된 메트릭으로 Pod 수 조절 결정
수집된 데이터를 바탕으로 스케일링이 필요한지 판단한 후, Deployment 등의 리소스에 반영해 Pod 개수를 자동 조정.
4.2. 스케일링 기준
원하는 레플리카 수 = 현재 레플리카 수 X (현재 메트릭 값 / 원하는 메트릭 값)
4.3. 실습(1): HPA 환경 구축(Metric Server 설치)
쿠버네티스에서 Auto Scailing을 하려면 현재 파드나 노드가 얼마나 자원을 사용하는지 모니터링할 수 있어야 한다. 이를 위해 Kubernetes에서는 Metric Server라는 경량화된 리소스 수집기를 사용한다.
✔ Metric Server란?
Kubernetes 클러스터 내 리소스 사용량(CPU, 메모리 등)을 수집하는 서비스를 말하며, kubectl top 명령어를 사용하려면 Metric Server가 반드시 설치되어 있어야 한다. 보통 HPA의 작동 기반이 되는 메트릭 데이터를 제공한다.
4.3.1. Metric Server 설치
# 기존 Metric Server 삭제 (이미 설치된 경우)
kubectl delete -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# Metric Server 설치
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
4.3.2. Metric Server 정상 작동 확인
kubectl get deployment metrics-server -n kube-system
4.3.3. Metric Server 설정 수정 (TLS 에러 대응)
Metric Server가 kubelet과 TLS 통신을 제대로 하지 못할 경우, 다음 설정을 수정해야 한다.
kubectl edit deployment metrics-server -n kube-system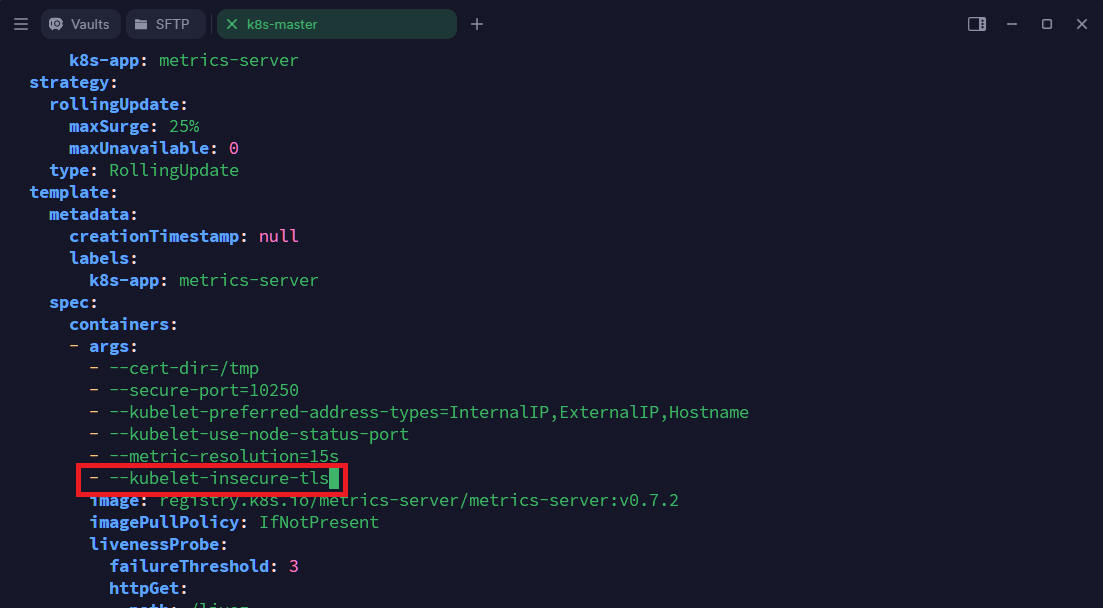
4.3.4. Metric 확인
Metric Server가 정상적으로 설치되었으면 다음 명령어로 클러스터 리소스 사용량을 확인할 수 있다.
kubectl top nodes
kubectl top nodes --sort-by=memory
kubectl top node --use-protocol-buffers
4.4. 실습(2): HPA 구성과 테스트
4.4.1. Deployment 생성
HPA의 대상이 될 Deployment 작성
vi hpa-deployment-01.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-deployment-01
spec:
replicas: 3
selector:
matchLabels:
app: hpa-web
template:
metadata:
labels:
app: hpa-web
spec:
containers:
- name: hpa-web-container
image: nginx:1.25
resources:
requests: # metrics로 참조할 cpu사용률
cpu: 50m
memory: 5Mi
limits:
cpu: 100m
memory: 20Mi
ports:
- containerPort: 80kubectl apply -f hpa-deployment-01.yaml
4.4.2. HPA 리소스 생성
vi hpa-01.yamlapiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-01
spec:
scaleTargetRef: # 대상 설정
apiVersion: apps/v1
kind: Deployment
name: hpa-deployment-01
minReplicas: 2 # replica 최소값
maxReplicas: 10 # replica 최대값
metrics: # replica수를 조정할 때 참조할 지표 설정
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # 스케일링 기준kubectl apply -f hpa-01.yaml
4.4.3. 리소스 확인
Pod가 현재 몇 개이며, 어떤 기준으로 스케일링하고 있는지 확인할 수 있다. 실시간으로 확인하고 싶다면 watch 명령어를 사용하면 된다.
# 리소스 생성 및 확인
kubectl apply -f hpa-deployment-01.yaml
kubectl get deployments.apps
kubectl get hpa
kubectl apply -f hpa-01.yaml
kubectl get hpa
# [새로운 터미널 : k8s-master]
watch -n1 -d kubectl get hpa
4.4.4. 부하 테스트
이 명령은 /dev/zero 파일에 대해 끝없는 계산을 수행하여 CPU를 지속적으로 사용하게 만든다. 이후 HPA가 작동하여 Pod 수가 늘어나는 것을 확인할 수 있다.
# 부하 테스트
kubectl exec 파드1 이름 -- sha256sum /dev/zero
위에서 보면 CPU 사용량이 설정해놓은 70%를 넘지 않아서 pod가 추가생성 되지 않았지만 만약 70%를 넘으면 `kubectl get pod`를 하면 새로운 pod가 추가된다. 이후 부하테스트를 강제 종료 시키면 CPU 사용량이 줄어들면서 새롭게 생성된 파드가 다시 삭제된다.
CA는 AWS Cloud의 EKS를 참고
'Kubernetes > Ops' 카테고리의 다른 글
| [17] Helm (0) | 2025.06.17 |
|---|---|
| [15] Kubernetes Deployment Strategy (0) | 2025.06.16 |
| [14] Kubernetes Scheduler (0) | 2025.06.16 |
| [13] Kubernetes Security (5) | 2025.06.14 |
| [2] Kubernetes 환경 구축 (0) | 2025.06.12 |