
0. 들어가며

위 Kafka 내부 구조 이미지를 보면 프로듀서가 브로커로 메시지를 전송하는 과정이 자세히 나와 있다. 프로듀서에서 생성된 ProducerRecord는 send() 호출을 통해 파티셔너(Partitioner)로 전달되고, 파티셔너는 이 메시지가 토픽의 여러 파티션 중 어디로 가야 할지 결정한다. 이후 파티션이 결정된 메시지들은 배치(Batch)로 묶여 실제 브로커로 전송된다.
그런데 여기서 중요한 점은, 메시지를 브로커로 보내기 전에 반드시 거쳐야 하는 과정이 하나 더 있다는 것이다. 바로 직렬화(Serialize)다. 이 글에서는 프로듀서가 메시지를 브로커로 전송할 때 거치는 직렬화 과정과 파티셔닝 과정을 자세히 살펴보도록 하겠다.
1. Serialize/Deserialize (직렬화/역직렬화)
1.1. 직렬화의 개념

- 프로듀서가 브로커로 메시지를 전송할 때는 반드시 직렬화(Serialize)된 형태여야 한다. 반대로 컨슈머는 브로커로부터 직렬화된 메시지를 받아 역직렬화(Deserialize)하는 과정을 거친다. 이는 카프카 브로커가 바이트 배열(Byte Array) 형태의 데이터만 처리하도록 설계되었기 때문이다.
- Producer가 전송하는 메시지(Record)의 key 값이 1000이고 value가 "홍길동"이라면, 이 key와 value는 반드시 `byte[]` 형식으로 직렬화되어야 한다. Consumer도 마찬가지로 브로커로부터 `byte[]` 형태의 직렬화된 메시지를 가져온 뒤, 역직렬화(Deserialize) 과정을 통해 원래의 Key와 Value로 복원하게 된다.
1.2. 자바 객체의 직렬화
객체 직렬화란 객체의 상태(필드 값)를 바이트 스트림(Byte Stream) 형태로 변환하는 과정을 말한다. 이를 통해 객체는 다음과 같은 이점을 얻을 수 있다.
- 시스템 간 이동: 서로 다른 JVM이나 물리적으로 분리된 시스템 간에 객체를 자유롭게 전송할 수 있다.
- 영속성(Persistence): 객체를 파일 형태로 저장하거나 데이터베이스에 보관했다가 나중에 다시 복원할 수 있다.
즉, 직렬화와 역직렬화는 네트워크를 통한 노드 간 데이터 전송과 저장을 가능하게 하는 핵심 기술이다.
1.3. Producer와 Consumer에서의 직렬화/역직렬화 적용
Java 클라이언트에서 직렬화/역직렬화 설정은 프로듀서와 컨슈머 각각 Properties 객체에 관련 클래스를 지정하는 방식으로 이루어진다. 프로듀서는 직렬화(Serializer)를, 컨슈머는 역직렬화(Deserializer)를 설정한다.
1.3.1. Java Producer Client – Key: String, Value: String
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.101:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName,"hello world 2");
kafkaProducer.send(producerRecord);1.3.2. Java Consumer Client – Key: String, Value: String
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.101:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "simple-group");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(props);1.4. Kafka에서 기본 제공하는 Serializer
카프카는 다양한 기본 타입에 대한 Serializer를 기본으로 제공한다.
- `StringSerializer`
- `ShortSerializer`
- `IntegerSerializer`
- `LongSerializer`
- `DoubleSerializer`
- `BytesSerializer`
2. Partitioning
2.1. Key 값을 가지지 않는 메시지의 파티셔닝
2.1.1. 특징
- Producer가 메시지를 전송할 때, `Partitioner`는 해당 메시지가 토픽의 어떤 파티션으로 전송될지를 결정한다.
- Key 값이 없는 메시지의 경우, 라운드 로빈(Round Robin)이나 스티키 파티셔닝(Sticky Partitioning)과 같은 전략에 따라 파티션이 선택된다.
- 토픽이 여러 개의 파티션을 가질 때, 메시지의 전송 순서는 보장되지 않는다.
2.1.2. 시나리오 이해
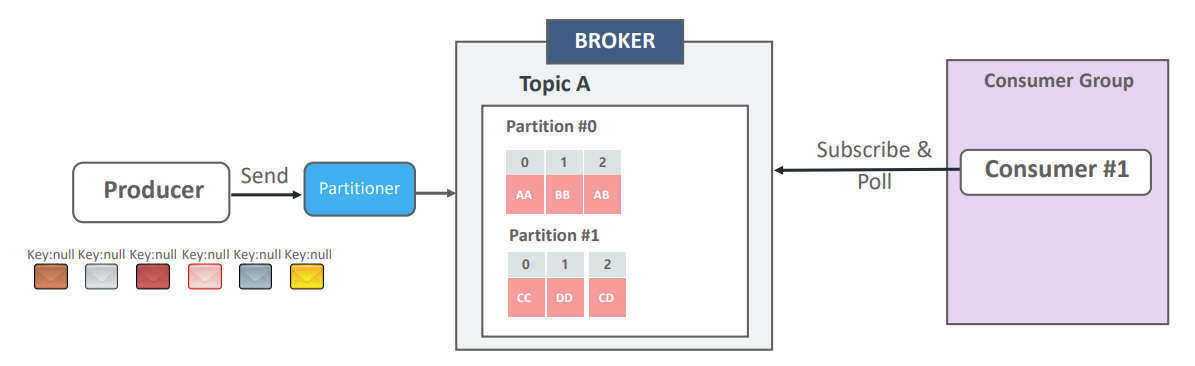
예를 들어 (AA), (CC), (BB), (DD), (AB), (CD) 순서로 메시지를 전송했다고 가정해보자. 위 그림과 같이 Partition 0에는 (0,AA), (1,BB), (2,AB)가 저장되고, Partition 1에는 (0,CC), (1,DD), (2,CD)가 저장될 수 있다.
만약 Consumer #1이 Partition 0만 담당한다면, 이 Consumer는 (AA), (BB), (AB)만 읽게 된다. 즉, 원래 전송 순서인 첫 번째, 두 번째, 세 번째, 네 번째, 다섯 번째, 여섯 번째 순서가 아니라, 첫 번째, 세 번째, 다섯 번째 데이터만 읽히는 문제가 발생한다.
이러한 전송 순서 비보장은 분산 시스템이 가진 고질적인 특성이다. 파티션이 2개면 병렬도는 2, 파티션이 10개면 병렬도는 10이 된다. 각 파티션 간의 순서는 보장할 수 없다는 단점이 있지만, 각 파티션 내에서는 순서를 보장하며 높은 병렬성과 성능을 얻는 장점이 있다. 즉, 트레이드오프(Trade-off)인 셈이다.
2.1.3. Key 값을 가지지 않는 메시지의 파티션 분배 전략
Key가 없는 메시지를 어떤 방식으로 파티션에 분배할지에 대한 전략은 크게 두 가지로 나뉜다.
- [1] 라운드 로빈(Round Robin): Kafka 2.4 버전 이전의 기본 파티션 분배 전략
- [2] 스티키 파티셔닝(Sticky Partitioning): Kafka 2.4 버전부터 도입된 기본 파티션 분배 전략
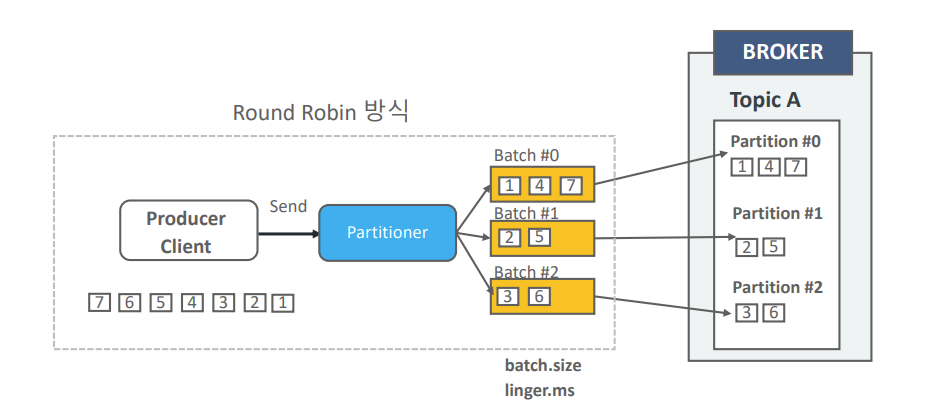
- 라운드 로빈 방식의 문제점: 라운드 로빈은 메시지를 최대한 균일하게 분배하려는 전략이다. 하지만 각 파티션으로 가는 배치(Batch)를 빨리 채우지 못하면 전송이 지연되거나, 배치를 다 채우지 못한 상태에서 전송이 이루어져 네트워크 효율이 떨어지는 문제가 발생한다.
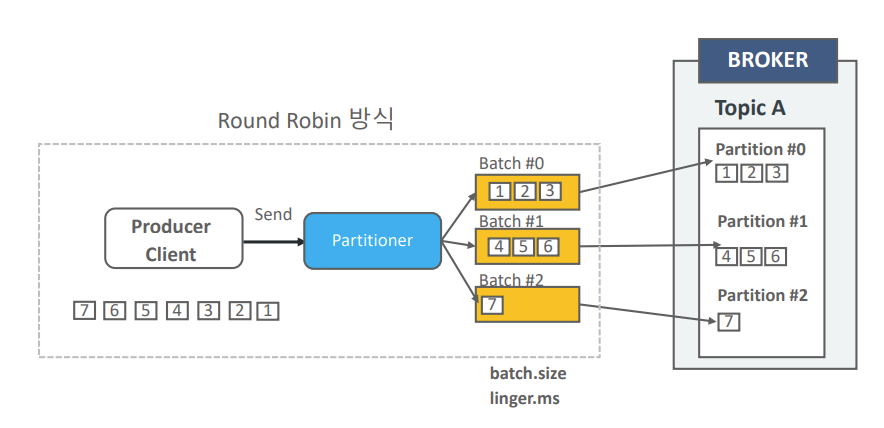
- 스티키 파티셔닝의 장점: 스티키 파티셔닝은 라운드 로빈의 성능 문제를 개선하기 위해 도입되었다. 특정 파티션으로 전송되는 하나의 배치에 메시지를 빠르게 먼저 채워서 보내는 방식이다. 즉, 일단 하나의 배치를 꽉 채우는 데 집중함으로써 배치를 채우지 못해 전송이 지연되거나, 작은 배치가 자주 전송되는 문제를 해결한다.
2.2. Key 값을 가지는 메시지의 파티셔닝
"순서를 보장할 수 없다면 분산 서비스를 이용해 고성능을 내더라도 정상적인 서비스가 불가능한 것 아닌가?"라는 의문이 들 수 있다. 카프카는 이러한 문제를 해결하기 위해 메시지 Key라는 개념을 제공한다.
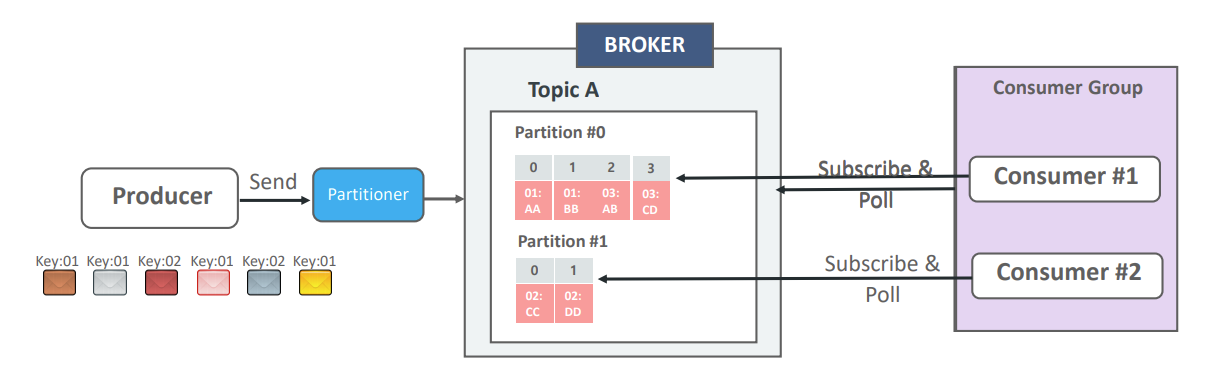
- 메시지 Key는 업무 로직이나 메시지 처리 시 분산 성능 영향을 고려하여 생성된다.
- 특정 Key 값을 가지는 메시지는 항상 동일한 파티션으로 고정되어 전송된다.
- 따라서 특정 Key 값을 가지는 메시지는 단일 파티션 내에서 전송 순서가 보장되며, Consumer에서도 그 순서대로 읽히게 된다.
- 카프카는 하나의 파티션 내에서만 메시지의 순서를 보장한다는 원칙을 기억하자. (예: key=01인 메시지가 이전에 Partition 0으로 들어갔다면, 다음 key=01 메시지도 무조건 Partition 0으로 들어간다.)
- Consumer는 보통 각 파티션당 하나씩 할당되어 데이터를 처리한다.
Producer가 `send()`를 호출할 때, 키의 존재 여부에 따라 파티셔닝 동작은 다음과 같이 나뉜다.
- Key가 있는 경우: 키를 해시(Hash)하여 특정 파티션을 결정한다. (예: `hash(key) % 3` 계산 결과가 2라면 파티션 2로 전송)
- Key가 없는 경우 (null): 스티키 파티셔닝(Sticky Partitioning) 전략에 따라 특정 배치가 찰 때까지 하나의 파티션에 메시지를 몰아넣고, 배치가 차면 다음 파티션으로 넘어간다.
2.3. 실습을 통해 확인하는 파티셔닝
2.3.1. 실습 [1]: Key 값을 가지는 메시지 전송 (단일 Partition)
1. Producer에서 Key 메시지 전송
kafka-console-producer --bootstrap-server localhost:9092 --topic test-topic \
--property key.separator=: --property parse.key=true
>01:aaa
>02:bbb
>01:ccc
>02:ddd2. Consumer에서 Key 메시지 읽기
kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic \
--property print.key=true --property print.value=true --from-beginning
01 aaa
02 bbb
01 ccc
02 ddd동일한 Key(01, 02)를 가진 메시지들이 순서대로 잘 출력되는 것을 확인할 수 있다.
2.3.2. 실습 [2]: Key 값을 가지지 않는 메시지 전송 (다중 Partition)
1. 3개의 파티션을 가진 Topic 생성
kafka-topics --bootstrap-server localhost:9092 --create --topic multipart-topic --partitions 32. Consumer 실행하여 메시지 읽기 대기
kafka-console-consumer --bootstrap-server localhost:9092 --topic multipart-topic3. Producer로 메시지 전송
kafka-console-producer --bootstrap-server localhost:9092 --topic multipart-topic
>aaa
>bbb
>ccc
>ddd
>eee
위처럼 aaa, bbb, ccc, ...를 입력하면 Consumer 입장에서는 순서대로 잘 전달된다. "어? 아까전에 Multi Partition 환경에서는 순서가 보장되지 않는다고 했는데?" 라고 생각이 들 수 있다. 생각과 마찬가지로 멀티 파티션 환경에서는 순서가 보장되지 않는다. 다만, 현재 내가 입력하는 시간이 느리기 때문에 순서가 꼬이기전에 Consumer가 Message를 가져가는 속도가 더 빨라서 문제가 생기지 않을 뿐이다. 이에 대한 반증으로 아래를 확인해보자.
4. Consumer로 파티션 정보 확인
kafka-console-consumer --bootstrap-server localhost:9092 --topic multipart-topic \
--from-beginning --property print.partition=true
순서대로 다시 읽어왔을 때 어떻게 읽어왔는지 확인해보자. 각 파티션 별로 Partition #0은 aaa, ccc, eee 순서로 가져오고, Partition #1은 bbb,ddd 순서로 가져온다. Consumer #1이 Partition #0을 읽으면 aaa, ccc, eee를 읽게 되고, Consumer #2가 Partition #1을 읽으면 bbb, ddd를 읽게 된다. 즉, 메시지의 순서를 보장하지 못한다는 것을 알 수 있다.
참고로 Consumer는 Message를 가져올 때 파티션 별로 데이터를 한꺼번에 가져오는 "배치 처리" 방식을 이용한다.
2.3.3. 실습 [3]: Key 값을 가지는 메시지 전송 (다중 Partition)
1. Producer에서 Key 메시지 전송
kafka-console-producer --bootstrap-server localhost:9092 --topic multipart-topic \
--property key.separator=: --property parse.key=true
1:aaa
2:bbb
3:ccc
4:ddd
5:eee
6:fff2. Consumer에서 Key와 파티션 정보 확인
kafka-console-consumer --bootstrap-server localhost:9092 --topic multipart-topic \
--property print.key=true --property print.value=true \
--property print.partition=true
Partition:0 1 aaa
Partition:2 2 bbb
Partition:2 3 ccc
Partition:1 4 ddd
Partition:0 5 eee
Partition:1 6 fff3. 동일한 Key로 메시지 재전송
아까 위에서 key값이 있는 경우에는 이전에 설정된 Partition #n에 고정되어 들어간다고 했다. 실제로 1:aaa 값은 Partition:0으로 이전에 배치되었는데, 이번에는 1:kkk를 했을 때 똑같이 Partition:0으로 설정되는지 확인해보자.


예상한대로 key값이 1인 경우, aaa를 kkk로 바꾸더라도 이전에 key:1이 Partition:0에 배치되었었기 때문에 이번에도 Partition:0으로 고정되어 들어가게 되는것을 확인할 수 있다.
2.3.4. 실습 [4]: Key 값을 가지지 않는 메시지 대량 전송 (단일 Partition)
1. Consumer에서 메시지 수신 대기
kafka-console-consumer --bootstrap-server localhost:9092 --topic multipart-topic \
--property print.key=true --property print.value=true --property print.partition=true2. 대량의 Non-key 메시지 준비 및 전송
# load.log 파일 생성 및 2000개 메시지 기록
touch load.log
for i in {1..2000}
do
echo "test nonkey message sent test00000000000000 $i" >> load.log
done
# load.log 파일 기반 메시지 전송
kafka-console-producer --bootstrap-server localhost:9092 --topic multipart-topic < load.log3. 결과 확인
Consumer 로그를 보면 다음과 같이 특정 파티션에 메시지가 몰려 있다가, 배치가 차면 다음 파티션으로 넘어가는 스티키 파티셔닝의 동작을 확인할 수 있다.
Partition:2 null test nonkey message sent test0000000000000 306
Partition:2 null test nonkey message sent test0000000000000 307
...
Partition:0 null test nonkey message sent test0000000000000 513
Partition:0 null test nonkey message sent test0000000000000 514
...
Partition:1 null test nonkey message sent test0000000000000 1
Partition:1 null test nonkey message sent test0000000000000 23. Kafka 직렬화와 파티셔닝 핵심 요약 (⭐)
- Kafka는 Producer - Broker - Consumer 구조를 가지고 있다. 브로커는 바이트 배열(byte[]) 형태의 데이터만 처리할 수 있기 때문에, 프로듀서는 메시지를 보낼 때 직렬화를 반드시 수행해야 하며, 컨슈머는 브로커로부터 받은 바이트 배열을 다시 역직렬화하여 원래 메시지로 복원한다.
- 직렬화/역직렬화할 때 Java에서는 Properties 객체를 사용하여 직접 Serializer/Deserializer 클래스를 지정한다. (Spring Kafka에서는 `application.yml`에 설정만 하면 AutoConfiguration이 자동으로 처리해준다. 즉, 개발자가 직접 `KafkaProducer` 객체를 생성하거나 `close()`를 호출할 필요가 없다.)
- 파티셔닝은 병렬 처리로 인한 성능 향상이라는 큰 장점이 있다. 또한 파티션 내부적으로는 메시지 순서가 완벽하게 보장된다. 단, 파티션이 2개 이상일 경우 A파티션과 B파티션 간의 메시지 순서는 보장되지 않는다는 트레이드오프(Trade-off)가 존재한다.
- 메시지 순서가 보장되지 않는다는 점이 "망한 시스템"이라고 생각할 수 있지만, Kafka는 Key를 통해 이 문제를 해결한다. Key 값을 해시(Hash)하여 특정 Key를 가진 메시지는 항상 동일한 파티션에 할당되도록 강제할 수 있기 때문에, 해당 Key 범위 내에서는 완벽한 순서 보장이 가능하다.
- Key 사용 여부와 멀티 파티션 여부에 따른 동작 방식 정리
| 구분 | 단일 파티션 (Partitions=1) | 멀티 파티션 (Partitions≥2) |
| Key 없음 (null) | • 모든 메시지가 유일한 파티션(0번)으로 전송됨 • 전체 메시지 순서 보장됨 • 실전에서는 거의 사용하지 않는 구조 |
• 스티키 파티셔닝 또는 라운드 로빈으로 분산 저장 • 파티션 간 메시지 순서 보장되지 않음 • Consumer 그룹을 통한 병렬 처리 가능 |
| Key 있음 (예: "user-1") |
• Key 유무와 관계없이 모든 메시지가 동일한 파티션으로 전송됨 • 전체 메시지 순서 보장됨 • Key를 사용하는 의미가 없음 |
• 동일한 Key를 가진 메시지는 항상 동일한 파티션으로 전송됨 • Key 단위(특정 사용자, 특정 주문)로 순서 보장됨 • 서로 다른 Key의 메시지는 다른 파티션에 저장되어 병렬 처리 가능 → 가장 이상적인 조합 |
💡 실무 팁
1. 순서가 중요하고, 처리량도 높여야 한다면? → Key를 활용하여 멀티 파티션 구성
2. 모든 메시지의 전체 순서가 100% 보장되어야 한다면? → 파티션 1개 (단, 처리량은 희생)
3. 순서는 중요하지 않고 빠른 처리만 필요하다면? → Key 없이 멀티 파티션 구성
'Kafka > Core' 카테고리의 다른 글
| [BASIC #7] Config 구분 및 이해: 카프카 설정의 계층 구조 파악하기 (0) | 2025.09.07 |
|---|---|
| [BASIC #6] Consumer의 핵심: Consumer Group과 리밸런싱 전략 (0) | 2025.09.07 |
| [BASIC #4] 메시지 전송의 시작: Producer와 Consumer (0) | 2025.09.07 |
| [BASIC #3] Kafka 3가지 핵심 요소: Topic, Partition, Offsets (0) | 2025.09.07 |
| [BASIC #2] 실습 환경 구축 및 실행 (0) | 2025.09.07 |