
0. 들어가며
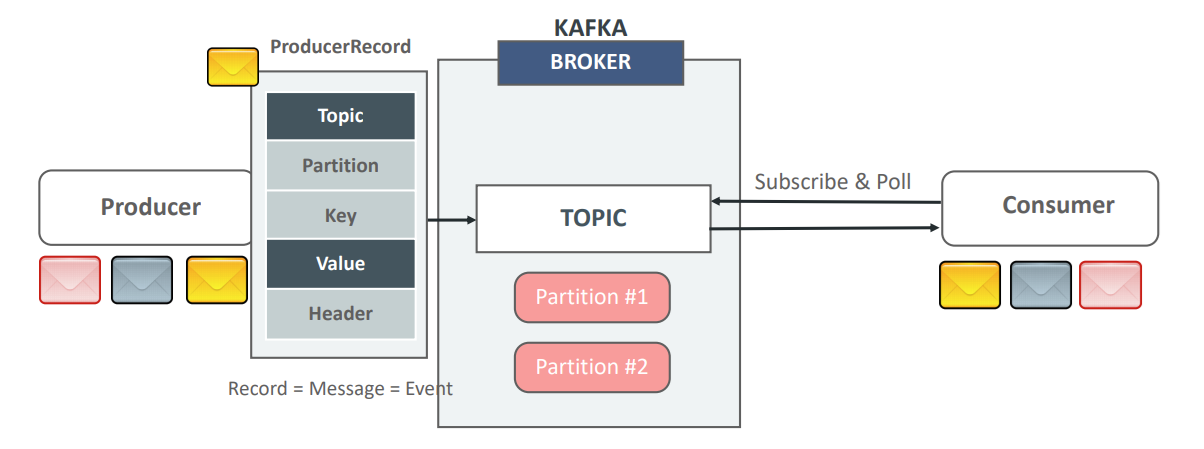
지난 글에서는 카프카에 데이터가 저장되는 물리적인 공간인 토픽, 파티션, 오프셋에 대해 알아보았다. 이번에는 그 저장소에 데이터를 넣고 빼는 가장 핵심적인 두 주체, 바로 프로듀서(Producer)와 컨슈머(Consumer)에 대해 이야기해보려 한다. 프로듀서와 컨슈머는 카프카 시스템의 입구와 출구와도 같아서, 이들의 동작 원리를 이해하는 것은 카프카를 활용하는 애플리케이션을 개발하는 첫걸음이라고 할 수 있다.
1. Producer: 카프카에 데이터를 쓰는 사람
프로듀서는 카프카 토픽으로 메시지를 보내는(쓰기, Write) 역할을 담당한다. 단순히 메시지를 전송하는 것처럼 보이지만, 프로듀서 내부에서는 생각보다 복잡하고 전략적인 결정들이 수행된다.
- 파티션 결정의 전략: 프로듀서는 메시지를 특정 토픽으로 보낼 때, 해당 토픽의 여러 파티션 중 어느 파티션으로 메시지를 보낼지 결정해야 한다. 이 결정은 단순히 랜덤이 아니다. 성능(처리량), 로드밸런싱(부하 분산), 가용성(장애 대비), 업무 정합성(메시지 순서) 등을 종합적으로 고려한 전략적인 판단의 결과이다.
- 레코드의 구성 요소:
- 필수 요소: 프로듀서가 보내는 레코드(메시지)에는 반드시 토픽(Topic) 이름과 실제 데이터인 값(Value) 이 포함되어야 한다.
- 선택 요소: 반드시 포함하지 않아도 되는 요소로는 파티션 번호(Partition), 메시지를 식별하는 키(Key), 그리고 메시지에 대한 추가 정보를 담는 헤더(Header) 등이 있다. 키의 유무는 이후 메시지가 특정 파티션에 할당되는 방식에 큰 영향을 미친다.
2. Consumer: 카프카에서 데이터를 읽는 사람
컨슈머는 프로듀서와 반대로, 토픽에 저장된 메시지를 읽어오는(읽기, Read) 역할을 한다.
- Subscribe & Poll 모델: 컨슈머는 자신이 읽고 싶은 토픽을 구독(Subscribe)한 후, 지속적으로 poll() 메서드를 호출하여 새로운 메시지가 있는지 확인한다. 이는 컨슈머가 브로커에게 "새 메시지 있어?"라고 능동적으로 물어보는 방식이다.
- 데이터의 지속성: 여기서 아주 중요한 점은 컨슈머가 메시지를 읽어가더라도, 그 메시지는 파티션에서 사라지지 않는다는 것이다. 컨슈머는 단순히 파티션 로그 파일의 특정 위치(오프셋)까지 읽기 포인터를 이동시킬 뿐, 원본 데이터는 그대로 남아 있다. 따라서 여러 개의 다른 컨슈머 그룹이 동일한 데이터를 각자의 속도로 여러 번 읽어갈 수도 있다.

3. Producer & Consumer CLI 실습
이론으로 배운 내용을 이제 실제 커맨드 라인 인터페이스(CLI)를 통해 직접 경험해보자. 두 개의 터미널 창을 각각 프로듀서와 컨슈머 용도로 준비한다.

3.1. Producer: 메시지 전송하기
3.1.1. 토픽 생성 및 Producer 실행
가장 먼저 실습에 사용할 토픽을 생성하고, 콘솔 프로듀서를 실행한다.
# 1. 토픽 생성
kafka-topics --bootstrap-server localhost:9092 --create --topic test-topic
# 2. 콘솔 프로듀서 실행
kafka-console-producer --bootstrap-server localhost:9092 --topic test-topic
>프롬프트(>)가 나타나면 메시지를 입력할 준비가 된 것이다. 아래와 같이 세 줄의 메시지를 입력해보자.
> aaa
> bbb
> 1113.1.2. 내부 동작 흐름 상세히 보기
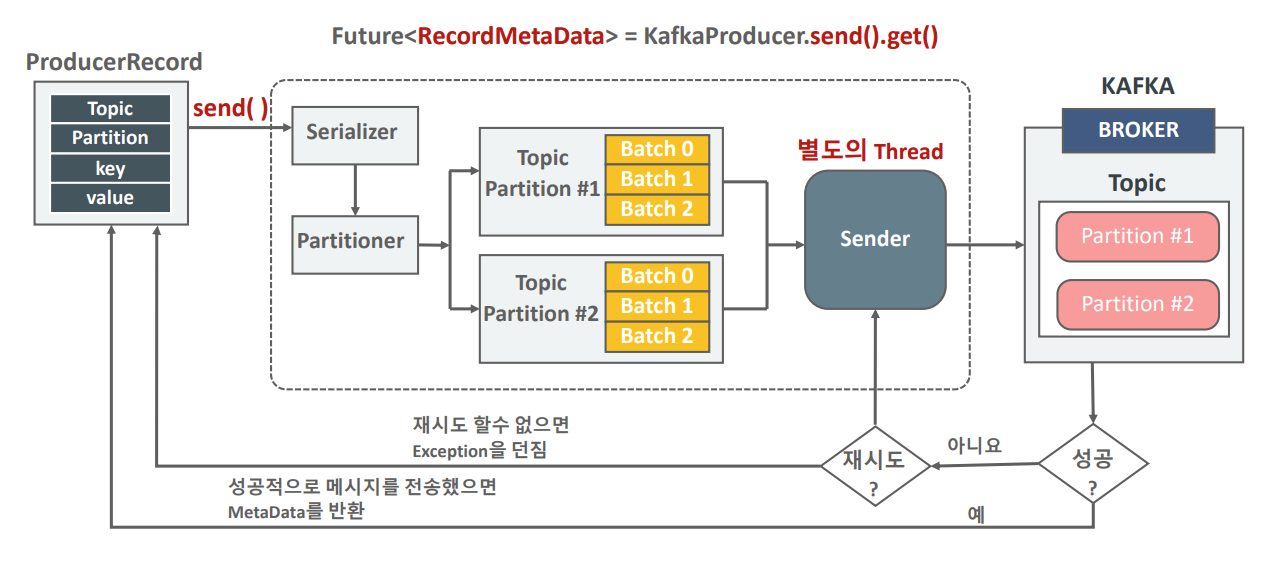
눈에는 보이지 않지만, 프로듀서가 메시지를 전송하는 순간 중요한 두 가지 단계가 내부적으로 수행된다.
[1] send() 호출 시점
- 직렬화(Serialize): 프로듀서는 입력받은 문자열(aaa, bbb, 111)을 네트워크 전송이 가능한 형태인 바이트 배열(Byte Code)로 변환한다. 여기서 숫자 111도 문자열로 인식되어 직렬화된다는 점을 기억하자.
- 파티셔닝(Partitioning): 직렬화된 메시지는 파티셔너에 의해 토픽 내의 특정 파티션으로 전송될 예정이다. (이번 실습에서는 파티션이 1개인 토픽을 사용하므로 모든 메시지는 0번 파티션으로 전송된다.)
결과적으로 프로듀서가 보낸 메시지는 브로커의 토픽 파티션에 (오프셋, 값) 형태로 저장된다.
- `aaa` -> (0, aaa)
- `bbb` -> (1, bbb)
- `111` -> (3, 111)
3.2. Consumer: 메시지 읽기
이제 다른 터미널 창에서 콘솔 컨슈머를 실행해보자.
3.2.1. 기본 Consumer 실행
kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic이 명령어를 실행해도 아무것도 출력되지 않을 것이다. 컨슈머가 실행된 이후에 새롭게 전송된 메시지만 보여주기 때문이다. 이미 저장되어 있는 메시지는 보여주지 않는다. 잠시 후 프로듀서 창에서 새로운 메시지를 하나 더 보내면, 이 컨슈머가 즉시 그 메시지를 수신하는 것을 확인할 수 있다.
3.2.2. `auto.offset.reset` 설정의 이해
그렇다면 기존에 저장되어 있던 메시지(`aaa`, `bbb`, `111`)는 어떻게 읽어올 수 있을까? 이때 필요한 설정이 바로 `auto.offset.reset` 이다. 이 설정은 컨슈머 그룹이 특정 파티션에 대해 읽기 시작할 오프셋(offset) 정보가 없을 때(예: 처음 접속했을 때) 어디서부터 읽을지를 결정한다.
- `earliest`: 파티션의 가장 처음 오프셋(0번)부터 모든 데이터를 읽어온다.
- `latest` (기본값): 컨슈머가 실행된 이후부터 새로 들어오는 데이터만 읽어온다.
콘솔 컨슈머에서는 `--from-beginning` 옵션을 사용하는 것이 `auto.offset.reset=earliest`를 설정하는 것과 같다.
kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic --from-beginning
aaa
bbb
111이제 저장되어 있던 모든 메시지가 순서대로 출력되는 것을 확인할 수 있다.
4. 정리: Producer의 메시지 전송, 단계별로 이해하기
지금까지의 실습을 통해 프로듀서가 메시지를 전송할 때 단순히 '전송'이라는 하나의 동작으로 보이지만, 내부적으로는 다음과 같은 정교한 단계를 거친다는 것을 알 수 있다.
- `send()` 호출: 개발자가 작성한 코드(또는 콘솔 명령어)에서 `send()`를 호출한다.
- 직렬화(Serialize): 프로듀서 내부의 Serializer가 메시지의 Key와 Value를 바이트 배열(Byte Array)로 변환한다.
- 파티셔닝(Partitioning): Partitioner가 직렬화된 메시지를 토픽의 수많은 파티션 중 정확히 어느 파티션으로 보낼지 결정한다. 이 과정에서 메시지에 Key가 있으면 해시 값을 계산하여 특정 파티션을 지정하고, Key가 없으면 라운드 로빈(Round Robin)이나 스티키 파티셔닝(Sticky Partitioning) 전략에 따라 파티션을 선택한다.
- 브로커 저장: 최종적으로 선택된 파티션의 리더 브로커로 메시지가 전송되어 로그 파일의 끝에 추가된다.
이러한 단계적이고 전략적인 과정을 통해 카프카는 수많은 메시지를 빠르고 안정적으로 처리할 수 있는 것이다. 다음 글에서는 이 중에서도 특히 중요한 직렬화(Serialize)와 파티셔닝(Partitioning) 에 대해 더 깊이 파고들어 알아보겠다.
'Kafka > Core' 카테고리의 다른 글
| [BASIC #6] Consumer의 핵심: Consumer Group과 리밸런싱 전략 (0) | 2025.09.07 |
|---|---|
| [BASIC #5] Producer의 핵심: 직렬화와 파티셔닝 전략 (0) | 2025.09.07 |
| [BASIC #3] Kafka 3가지 핵심 요소: Topic, Partition, Offsets (0) | 2025.09.07 |
| [BASIC #2] 실습 환경 구축 및 실행 (0) | 2025.09.07 |
| [BASIC #1] 소개 (0) | 2025.09.06 |