
0. 들어가며

아파치 카프카는 단순하면서도 강력한 메시징 시스템이다. 그 힘의 비결은 데이터를 저장하고 관리하는 독특한 방식에 있다. 이번 글에서는 카프카의 데이터 저장소를 이해하기 위한 가장 기본이자 핵심인 토픽(Topic), 파티션(Partition), 그리고 오프셋(Offset) 개념에 대해 자세히 알아보겠다. 이 세 가지 개념은 카프카의 높은 성능과 안정성을 뒷받침하는 튼튼한 기반이 된다.
1. Kafka Topic: 데이터의 분류 체계
토픽은 카프카에서 메시지를 구분하는 가장 기본적인 단위이다. 데이터베이스의 '테이블(Table)'과 유사한 개념으로, 특정 주제나 유형의 데이터를 모아두는 논리적인 공간이라고 생각하면 쉽다. 예를 들어 '주문(Order)' 토픽, '결제(Payment)' 토픽, '배송(Delivery)' 토픽과 같이 데이터의 흐름을 주제별로 분류하는 역할을 한다.

- 로그 파일 형태: 토픽은 데이터가 시간 순서대로 계속해서 추가(Append-only) 되는 로그 파일 구조를 가진다. 한 번 저장된 데이터는 수정(Update)하거나 삭제(Delete)할 수 없다. 이러한 단순한 구조는 카프카가 복잡한 데이터 관리를 하지 않아도 되게 하여, 엄청나게 높은 처리 성능을 보장하는 핵심 비결이다.
- 유연한 데이터 구조: 메시지는 Key-Value 형태로 구성된다. 중요한 점은 직렬화(Serialize)만 가능하다면 어떤 형태의 데이터라도 저장할 수 있다는 것이다. 단순한 문자열(String)부터 JSON, Avro, 심지어 복잡한 프로그래밍 객체(Object)까지 유연하게 담을 수 있다.
2. Kafka Partition(파티션): 병렬 처리의 핵심
하나의 토픽은 여러 개의 파티션으로 나뉠 수 있다. 파티션은 카프카의 병렬 처리와 무한한 확장성을 가능하게 하는 가장 중요한 요소이다.

- 데이터 분산 저장: 프로듀서(Producer)가 보낸 메시지는 하나의 토픽 내에 존재하는 여러 파티션에 분산되어 저장된다. 마치 하나의 창고에 물건을 여러 개의 컨베이어 벨트로 나누어 보내는 것과 같다. 이를 통해 단일 시스템의 처리 한계를 넘어, 대규모의 데이터를 동시에 처리할 수 있는 길이 열린다.
- 독립적인 저장 단위: 각 파티션은 서로에게 전혀 영향을 주지 않는 완전히 독립적인 로그 파일이다. 따라서 데이터의 순서와 고유 번호(Offset)는 파티션 내에서만 보장된다. 파티션 0의 1번 메시지와 파티션 1의 1번 메시지는 전혀 다른 데이터이며, 순서도 비교할 수 없다.
- 핵심 정리(⭐): 다중 브로커의 목적은 "장애 대비를 통한 가용성 보장"에 있고, 다중 파티션의 목적은 "작업 분산을 통한 처리량 극대화"에 있다.
3. Kafka Offset: 데이터의 고유 주소
오프셋은 각 파티션 내에서 메시지가 저장된 정확한 위치를 나타내는 고유한 일련번호이다.

- 순차적 증가: 메시지가 파티션에 저장될 때마다 오프셋은 0부터 시작하여 1씩 순차적으로 증가한다. 마치 책의 페이지 번호와 같다.
- 불변성(Immutable): 한 번 할당된 오프셋과 그 위치의 데이터는 절대 변경되지 않는다. 이는 데이터의 무결성을 보장하는 중요한 특징이다.
- 컨슈머의 북마크: 컨슈머(Consumer)는 이 오프셋을 자신의 '책갈피'처럼 사용한다. 자신이 어디까지 데이터를 읽었는지 오프셋으로 기억하고 있다가, 설령 컨슈머에 장애가 발생하여 재시작되더라도 마지막으로 기록한 오프셋부터 다시 읽어들여 데이터의 중복이나 누락 없이 안전하게 작업을 재개할 수 있다.
4. Kafka Replication: 데이터 안정성 확보
카프카가 여러 대의 서버(브로커)에 데이터를 분산 저장하는 이유는 단순히 처리량을 높이기 위해서만은 아니다. 특정 브로커에 장애가 발생하면 그 브로커가 가진 파티션의 데이터가 유실될 수 있다는 심각한 위험이 따른다.
이 치명적인 문제를 해결하기 위해 카프카는 복제(Replication) 기능을 사용한다. 각 파티션의 복제본을 서로 다른 브로커에 생성하여 데이터의 고가용성(High Availability)과 내결함성(Fault Tolerance)을 보장한다.
- 리더(Leader)와 팔로워(Follower): 복제된 파티션들은 명확한 역할이 나뉜다. 모든 데이터의 읽기와 쓰기는 오직 리더 파티션을 통해서만 이루어진다. 그리고 나머지 복제본인 팔로워 파티션들은 리더의 데이터를 실시간으로 가져와 복제하는 '백업' 역할에 충실한다.
- 자동 장애 복구(Failover): 만약 리더 파티션이 있는 브로커에 갑작스러운 장애가 발생하면, 팔로워 파티션 중 하나가 즉시 새로운 리더로 승격된다. 클라이언트(Producer/Consumer)는 이 변화를 거의 인지하지 못하며, 서비스는 중단 없이 안정적으로 계속된다.
5. Topic과 Partion의 병렬 분산 처리
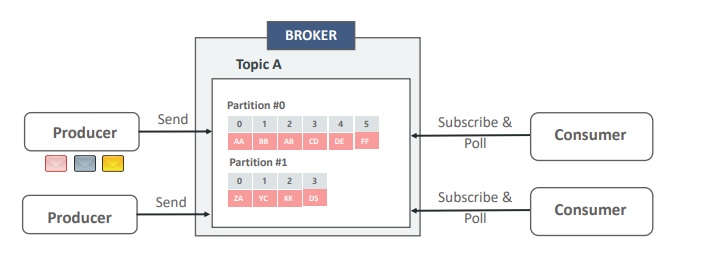
- 설명: 하나의 'Topic A'가 두 개의 파티션(Partition 0, Partition 1)으로 나뉘어져 있다. Producer는 'Topic A'로 메시지를 보내지만, 실제로는 Partitioner에 의해 결정된 규칙에 따라 메시지가 Partition 0 또는 Partition 1에 저장된다. 이 그림은 동일한 브로커(서버) 내에서도 파티션이 논리적으로 분리되어 데이터가 나뉘어 저장됨을 보여준다.

- 설명: 위의 개념이 확장된 모습이다. 'Topic A'의 파티션들이 이제는 물리적으로 분리된 두 개의 브로커(서버)에 나뉘어 저장된다. Partition #0은 Broker A에, Partition #1은 Broker B에 저장되어 있다. Producer는 여전히 'Topic A'로 메시지를 보내고, 카프카 클러스터는 내부적으로 각 메시지를 목적지 파티션이 위치한 정확한 브로커로 전달한다.
- 이렇게 파티션을 여러 브로커에 분산하면 처리 성능이 향상된다. 하지만 오른쪽 Broker(#B)에 장애가 발생했다고 가정해보자. Partition #1의 모든 데이터에 접근할 수 없게 되어, 결과적으로 전체 메시지의 절반이 유실되는 심각한 데이터 정합성 문제가 발생한다.

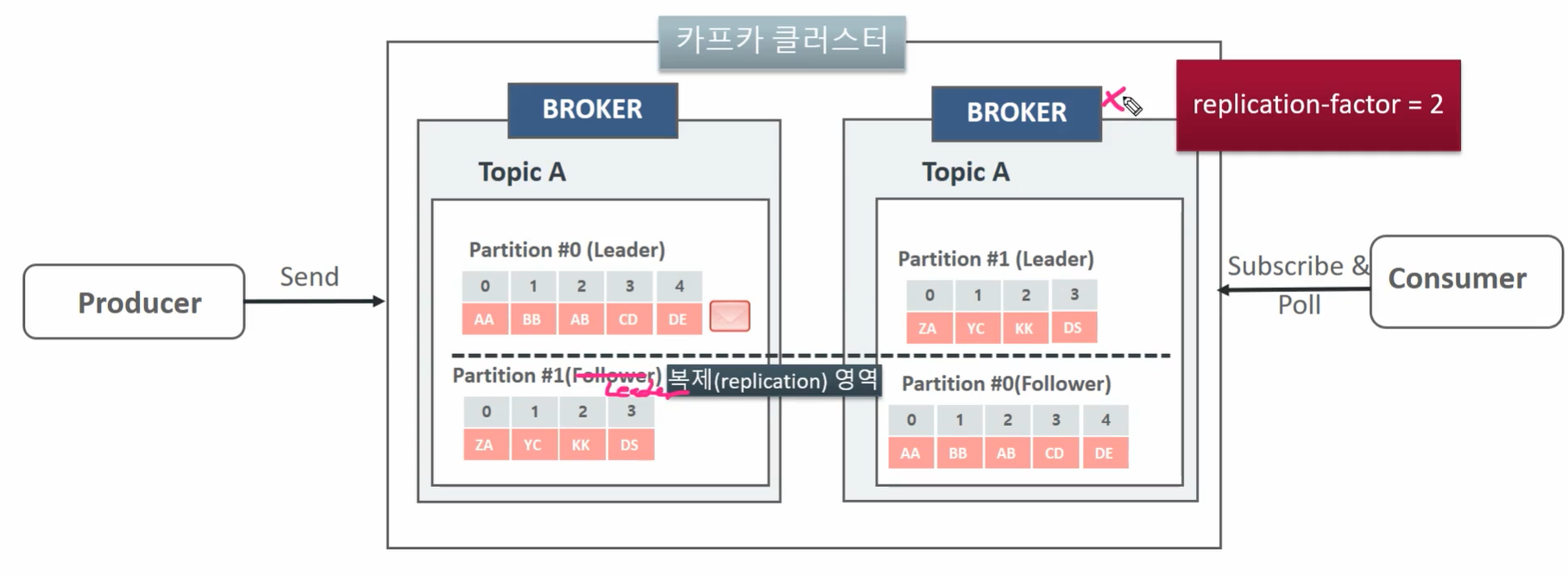
- 설명: 이 문제를 해결하기 위해 복제를 적용한 모습이다. replication-factor=2로 설정하여 각 파티션마다 하나의 복제본을 만들었다. 그 결과, 원본 파티션(Leader)은 기존 브로커에 남아있고, 복제본 파티션(Follower)은 다른 브로커에 생겨난다. 예를 들어, Broker #A에 있던 Partition #0(Leader)의 복제본(Partition 0-Follower)이 Broker #B에 생겨난다. 이제 데이터는 Leader로 들어오는 즉시 Follower에도 동기화되어 저장된다.
- 장애 복구 시나리오: 이제 만약 Broker B가 다운된다면 어떻게 될까? Broker #A에 있던 Partition #1의 복제본(원래는 Follower)이 새로운 Leader로 즉시 승격된다. 이후 Producer는 더 이상 다운된 Broker B로 메시지를 보내려 하지 않고, 새로운 Leader가 된 Broker #A의 Partition #1로 메시지를 보내게 된다. 이 과정을 통해 데이터 정합성은 완벽하게 유지된다.
- 트레이드오프: 물론 이러한 안정성은 공짜로 얻을 수 없다. 복제본을 저장해야 하므로 원래보다 2배의 저장 공간이 필요해진다. (예: 500MB면 충분했던 데이터가 이제는 1GB가 필요하다.)
6. Topic 실습
6.1. 기본 Topic
6.1.1. Topic 생성
kafka-topics --bootstrap-server localhost:9092 --create --topic test_topic_016.1.2. Topic 조회
kafka-topics --bootstrap-server localhost:9092 --list
6.2. 멀티 Partition 포함된 Topic
Kafka에서 분산 아키텍처의 핵심은 Partition이다. 따라서 토픽을 만들 때 여러개의 Partition을 만들어보자.
6.2.1. Topic 생성
kafka-topics --bootstrap-server localhost:9092 --create --topic test_topic_02 --partitions 36.2.2. Topic 조회
kafka-topics --bootstrap-server localhost:9092 --create --topic test_topic_02 --partitions 3
6.2.3. Topic 상세 조회 (describe)
kafka-topics --bootstrap-server localhost:9092 --describe --topic test_topic_02Topic: test_topic_02 TopicId: HAkvnv7rTLuRHhxy-YOupg PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test_topic_02 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: test_topic_02 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: test_topic_02 Partition: 2 Leader: 0 Replicas: 0 Isr: 0Partition이 0,1,2로 생성된것을 확인할 수 있다.
6.3. 복제 Topic 생성
6.3.1. Topic 생성
kafka-topics --bootstrap-server localhost:9092 --create --topic test_topic_03 --partitions 3 --replication-factor 26.3.2. 결과 확인
아래를 보면 알 수 있듯이, 현재는 단일 브로커라서 사용이 불가능하다는 Error가 발생한다. replicas는 기본적으로 두 개 이상의 Broker가 존재해야 사용할 수 있다.
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Error while executing topic command : Replication factor: 2 larger than available brokers: 1.
[2025-09-07 11:37:35,889] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.
(kafka.admin.TopicCommand$)'Kafka > Core' 카테고리의 다른 글
| [BASIC #6] Consumer의 핵심: Consumer Group과 리밸런싱 전략 (0) | 2025.09.07 |
|---|---|
| [BASIC #5] Producer의 핵심: 직렬화와 파티셔닝 전략 (0) | 2025.09.07 |
| [BASIC #4] 메시지 전송의 시작: Producer와 Consumer (0) | 2025.09.07 |
| [BASIC #2] 실습 환경 구축 및 실행 (0) | 2025.09.07 |
| [BASIC #1] 소개 (0) | 2025.09.06 |