
1. 카프카(Kafka): 데이터 시대의 중심을 관통하는 파이프라인
오늘날 전 세계 기업의 약 80%가 카프카를 사용하고 있다. 이 숫자는 카프카가 더 이상 특정 기업만 사용하는 기술이 아닌, 현대 데이터 아키텍처의 표준이 되었음을 의미한다.
그렇다면 카프카는 대체 무엇일까? 단순히 메시지를 전달하는 메신저일까? 아니다. 카프카의 본질은 모든 데이터가 거쳐가는 "중앙 택배 물류 허브" 와 같다. 시스템에서 발생하는 모든 '사건(Event)'들을 실시간으로 수집, 저장하고, 필요한 곳에 정확히 분배하는 데이터 시대의 심장부다.
2. 카프카는 왜 등장했는가? - '스파게티 아키텍처'의 저주를 풀다

카프카가 없던 시절을 상상해보자. '주문'이라는 데이터가 발생하면, 이 데이터를 필요로 하는 '재고', '배송', '데이터 분석' 시스템이 각자 '주문' 시스템에 직접 연결해야 했다. 처음엔 괜찮았지만, 연결할 시스템이 늘어날수록 구조는 걷잡을 수 없이 복잡해졌다.
이런 포인트-투-포인트(Point-to-Point) 구조는 '스파게티 아키텍처'라 불리며, 다음과 같은 재앙을 초래한다.
- 관리의 재앙: 새로운 시스템 하나를 추가하려면, 관련된 모든 시스템의 연결 코드를 수정하고 테스트해야 한다.
- 신뢰성의 문제: "배송 시스템에는 데이터가 갔는데, 분석 시스템에는 누락된 거 아니야?" 같은 데이터 정합성 문제가 끊임없이 발생한다.
- 시스템의 종속성: 데이터를 보내는 시스템이 받는 시스템의 상태에 직접적인 영향을 받는다. 재고 시스템이 잠시 다운되면 주문 시스템까지 문제가 전파될 수 있다.
카프카는 이 복잡성의 저주를 풀기 위해 등장했다. 데이터를 만드는 생산자(Producer)와 데이터를 쓰는 소비자(Consumer) 사이에 카프카라는 '중앙 물류 허브'를 두어 둘을 완벽하게 분리(Decoupling)한 것이다.
이제 생산자는 그냥 카프카라는 허브에 택배(데이터)를 맡기기만 하면 끝. 소비자는 자신이 필요한 택배를 허브에서 알아서 가져가면 그만이다. 구조는 극도로 단순해지고, 시스템 전체의 안정성과 확장성은 비약적으로 향상된다.
3. 그래서, 진짜 세상에서는 언제 쓰는 걸까?
[1] 마이크로서비스(MSA)의 숨통을 틔워주는 '중앙 분배 시스템'
여러 개의 작은 서비스가 모여 하나의 서비스를 이루는 MSA 환경에서, 카프카는 서비스 간의 통신을 책임지는 핵심 동맥 역할을 한다.
- Before Kafka: '주문 서비스'가 '재고', '배송', '알림' 서비스에 각각 전화를 걸어 "주문 들어왔어!"라고 알려줘야 하는 구조. 하나라도 통화에 실패하면 문제가 생긴다.
- After Kafka: '주문 서비스'는 카프카라는 중앙 광장에 "주문 발생!" 이라고 외치기만 하면 끝. '재고', '배송', '알림' 서비스는 광장에서 이 소식을 듣고 각자 할 일을 알아서 처리한다. 서로 누가 있는지도 알 필요가 없다.
[2] 대용량 실시간 데이터 처리의 '거대한 버퍼'
웹사이트에서 초당 수만 건씩 쏟아지는 사용자 클릭 로그, IoT 기기의 센서 데이터를 DB에 직접 넣는 것은 불가능에 가깝다.
카프카는 이런 대규모 데이터를 위한 거대한 임시 저장소(버퍼) 역할을 한다.
- 생산자 (웹서버 등): 발생하는 모든 데이터를 일단 빠르고 안전하게 카프카에 쌓아둔다.
- 소비자들: 각자의 목적에 맞게 카프카에서 데이터를 가져간다.
- 소비자 A: 데이터를 가져가 실시간 대시보드에 보여준다.
- 소비자 B: 데이터를 가져가 데이터 분석 시스템으로 보낸다.
- 소비자 C: 데이터를 가져가 장기 보관을 위해 데이터베이스에 저장한다.
하나의 데이터 흐름을 가지고, 여러 목적에 맞게 동시에, 그리고 각자 원하는 속도로 데이터를 활용할 수 있게 되는 것이다.
4. 카프카의 핵심 가치: 왜 모두가 열광하는가?
- 고성능과 확장성: 초당 수백만 건의 데이터를 처리하며, 부하가 늘어나면 서버(브로커)를 추가해 간단히 성능을 높일 수 있다.
- 높은 안정성과 내구성: 데이터를 여러 서버에 복제하여 저장하므로, 서버 하나가 다운되어도 데이터는 절대 유실되지 않는다. 수많은 금융권에서 트랜잭션 처리 시스템으로 사용하는 이유다.
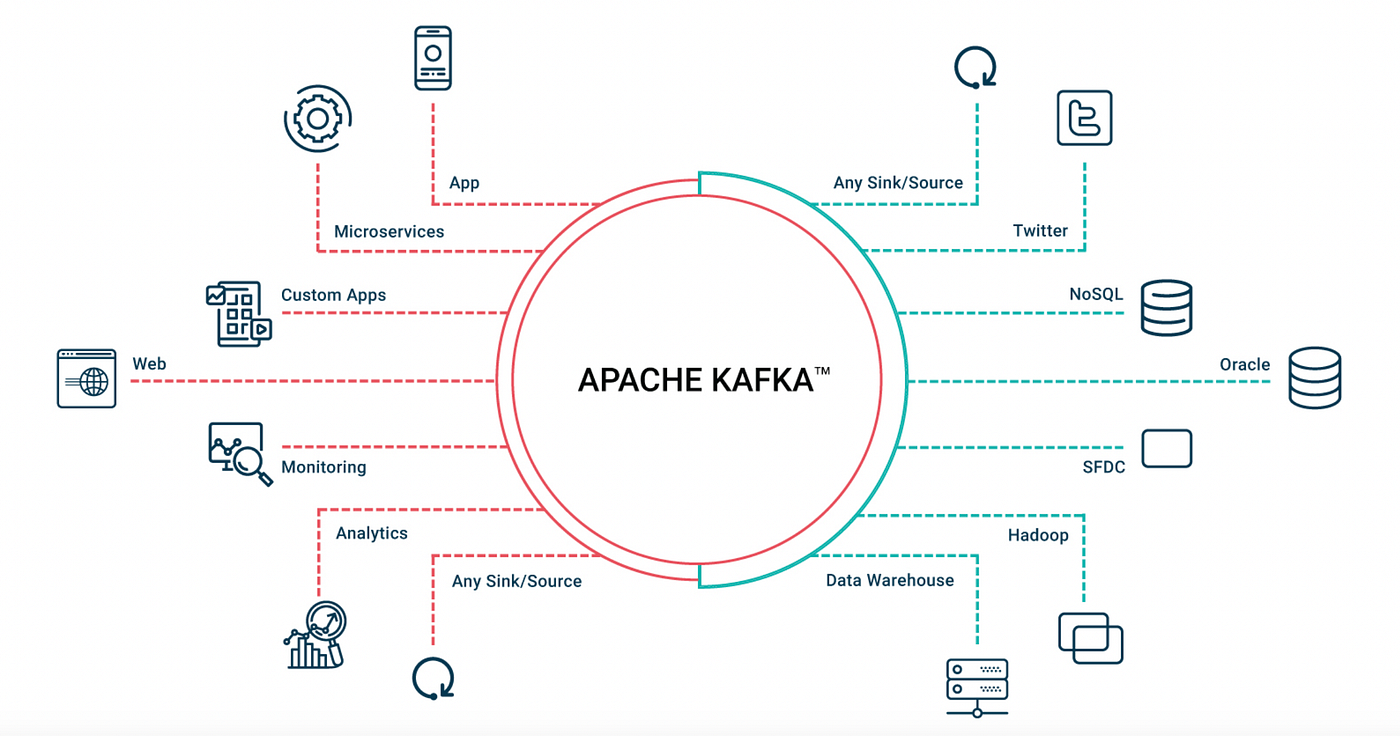
- 유연한 생태계: HDFS, Spark, 데이터베이스 등 거의 모든 종류의 데이터 플랫폼과 쉽게 연동할 수 있다. 카프카 커넥트(Kafka Connect)를 활용하면 코딩 없이 데이터 파이프라인을 구성할 수도 있다.
5. 아파치 카프카 vs 컨플루언트 카프카: 무엇을 선택할까?
카프카를 도입할 때, '순정 차량'과 '풀옵션 튜닝 차량' 중 하나를 선택할 수 있다.
- 아파치 카프카: 순정 차량. 카프카의 핵심 기능을 담은 100% 오픈소스다. 강력하지만, 운영에 필요한 관리 도구 등은 직접 만들어야 한다.
- 컨플루언트 카프카: 풀옵션 튜닝 차량. 아파치 카프카 엔진 위에 기업 환경에 필요한 강력한 관리 도구(Control Center), 데이터 스키마 관리(Schema Registry), 스트리밍 SQL(ksqlDB) 등을 추가한 상용 배포판이다. (무료 Community 버전도 제공된다.)
| 구분 | 아파치 카프카 | 컨플루언트 카프카 |
| 배포 형태 | 오픈소스, 직접 설치 및 운영 | Confluent에서 제공하는 배포판 (상용 + 무료 Community 버전) |
| 기능 | 기본적인 Pub/Sub, 스트리밍, 저장 | Kafka 기본 기능 + Confluent Platform 추가 기능 |
| 주요 추가 기능 | 없음 | Schema Registry, ksqlDB, Control Center, 확장된 커넥터 등 |
| 학습 난이도 | 비교적 높음 (모든 것을 직접 관리) | 상대적으로 낮음 (편의 기능 및 GUI 제공) |
| 주요 사용 사례 | 기본 스트리밍 처리, 오픈소스 환경 | 엔터프라이즈 환경, 운영 편의성 및 데이터 거버넌스가 중요할 때 |
실무 환경에서는 운영의 편의성과 안정성, 그리고 데이터 거버넌스를 위해 컨플루언트 플랫폼을 더 많이 활용하는 추세이다.
결론: 데이터가 흐르는 모든 곳에 카프카가 있다
데이터 기반 비즈니스가 기업의 성패를 가르는 시대. 카프카는 단순히 데이터를 옮기는 파이프라인을 넘어, 기업의 모든 데이터가 흐르는 중앙 데이터 허브이자 이벤트 기반 아키텍처의 심장으로 자리 잡았다. 카프카를 이해하는 것은 현대 IT 시스템의 혈관을 이해하는 것과 같다.
'Kafka > Core' 카테고리의 다른 글
| [BASIC #6] Consumer의 핵심: Consumer Group과 리밸런싱 전략 (0) | 2025.09.07 |
|---|---|
| [BASIC #5] Producer의 핵심: 직렬화와 파티셔닝 전략 (0) | 2025.09.07 |
| [BASIC #4] 메시지 전송의 시작: Producer와 Consumer (0) | 2025.09.07 |
| [BASIC #3] Kafka 3가지 핵심 요소: Topic, Partition, Offsets (0) | 2025.09.07 |
| [BASIC #2] 실습 환경 구축 및 실행 (0) | 2025.09.07 |